

1. 서론
2. 공간 빅데이터
1) 원격탐사 영상, 항공사진, 드론, CCTV 영상
2) 거리뷰 영상(street view image)
3) 택시, 버스, 개인의 이동궤적데이터
4) 소셜미디어 데이터
5) 사물인터넷(IoT: Internet of Things) 데이터
3. 인공지능 기술
1) 인공지능 개요
2) 딥러닝 모델의 종류
4. GeoAI 활용 분야
1) 국토 및 환경 모니터링
2) 도시연구
3) 감성 분석
4) 이동궤적 분석 및 예측
5) 지도학 및 매핑
5. 결론
1. 서론
최근 인공지능(Artifitial Intelligence)에 관한 관심이 뜨겁다. 우리나라에서는 2016년 구글 딥마인드에서 개발한 알파고가 이세돌과의 바둑에서 승리하고, 최근 오픈에이아이(Open AI)에서 개발한 ChatGPT(Chat Generative Pre-trained Transformer)가 공개되면서 높은 관심을 받고 있으며, 이러한 관심은 학계 및 산업계를 넘어 일반 대중에게까지 일상화되고 있다. 인공지능은 1950년대를 기점으로 학문적으로 활발하게 연구가 이루어지다가 침체기를 겪었고, 현재와 같은 본격적인 부흥의 시기를 맞게 된 것은 21세기라 할 수 있다. 21세기 인공지능이 급격한 발전을 이루게 된 요인에 대해 Hu et al.(2019b)은 첫째, 다양한 센서와 사용자들이 만드는 대용량의 빅데이터가 생성되고 수집이 가능지면서 이들 데이터에 대한 관찰과, 관찰에 기반한 미래 예측이 가능해진 점, 둘째, 인공지능 분야에서 통계학, 경제학, 생물학, 인지과학 등 주변 학문의 여러 아이디어를 가져오면서 새로운 알고리즘과 모델을 개발한 것, 셋째, 빅데이터와 새로운 모델을 연계하여 분석할 수 있는 고성능 컴퓨팅 하드웨어의 발전 때문이라고 설명하고 있다. 즉 빅데이터, 새로운 알고리즘, 그리고 컴퓨팅 하드웨어 성능의 발전은 인공지능 기술을 빠르게 발전시키는 계기가 되었다. 특히 2010년 중반 이후 인공지능 기술이 컴퓨터 비전1)1)이나 자연어처리 등에서 인간의 수준을 넘는 처리능력을 보이면서 다양한 도메인에서 이를 접목하는 계기를 만들었다. 인공지능 기술이 스마트 팩토리, 마케팅, 고객관리, 보안 관리, 군사, 의학 등 여러 도메인에 많은 영향을 미쳤으며 이는 공간정보 영역도 마찬가지이다.
지리학 및 공간정보 분야에서 AI(Artificial Intelligence)를 접목하려는 노력은 학계와 산업계 차원에서 이뤄지고 있다. GeoAI(Geospatial artificial intelligence)는 지리학, 또는 공간정보 학문영역과 인공지능 영역이 융합된 다학제 분야라 할 수 있다. 미국에서 2017년 ACM(Association for Computing Machinery) SIGSPATIAL(International Conference on Advances in Geographic Information System)에서 처음으로 GeoAI 워크숍이 개최되고 이미지처리, 교통 분야, 공중보건, 지역 연구 등에 GeoAI를 접목하는 연구가 발표되면서 이제는 하나의 영역으로 자리 잡아 가고 있다. GeoAI 연구와 관련하여 학계에서는 ‘지리학과 인공지능의 융합학문’ 또는 ‘지리적 지식 발견을 위해 공간적으로 명시적인 인공지능 기술’이라고 명명하며 GeoAI가 공간을 다루는 학문영역에서 고유한 분야로 발전하고 있음을 강조하고 있다(강영옥, 2023; Alastal and Shaqfa, 2022; Hu et al., 2019a; Janowicz et al., 2020; Lunga et al., 2022).
본 연구의 목적은 빠르게 발전하고 있는 GeoAI의 활용 분야와 최근 연구 동향을 분석하는 데 있다. 이를 위해 본 연구에서 분석대상은 2가지로 하였다. 첫째 국외 논문의 경우 2017년 SIGSPATIAL에서 GeoAI 워크숍이 개최된 이후 코로나로 행사를 개최하지 못한 2020년을 제외하고 2022년까지 발표된 논문들과 해당 분야와 관련하여 최근의 동향을 리뷰한 논문들을 대상으로 하였으며, 국내의 경우 NTIS 사이트에서 ‘딥러닝(deep learning)’을 키워드로 검색된 논문 가운데 지리학이나 공간정보를 명확하게 포함하는 논문을 대상으로 하였다. 특히 다음 몇 가지 측면에 초점을 두어 리뷰를 하였다. 첫째, 인공지능 기술은 포괄적 개념이며, 기존에 지리학에서 다뤄왔던 회귀분석이나 군집 분석 등도 인공지능 기술에 포함된다고 볼 수 있다. 하지만 본 연구에서는 인공지능 기술 가운데에도 딥러닝 기술을 활용한 사례에 초점을 두어 분석하였다. 둘째, 지리학이나 공간정보 분야에 딥러닝 기술을 활용하면서 가장 활발한 연구가 이루어진 분야는 원격탐사 분야일 것이다. 국내에서 원격탐사 영상에 딥러닝이 접목된 사례에 대해서는 몇 편의 리뷰 논문(김세형 등, 2022; 김형우 등, 2022; 류동우, 2019; 이창희 등, 2021)이 발표되었기 때문에 본 연구에서는 원격탐사 영상 분야를 포함하기는 하지만 원격탐사 영상 외 분야에 딥러닝 기술을 접목한 사례를 보다 중점적으로 살펴보고자 하였다.
본 논문의 2장에서는 활용 가능한 공간 빅데이터에 대해 살펴보고, 3장에서는 인공지능의 핵심기술과 방법론, 4장에서는 GeoAI의 활용 분야와 응용사례를 살펴보았다. 본 논문은 지리학 영역에서 핵심기술로 자리 잡아가고 있는 GeoAI의 최신 연구 동향과 사례를 소개함으로써 이 분야에 관심을 두는 연구자와 학자들에게 GeoAI 활용에 대한 통찰력과 최신 방법론 적용에 대한 아이디어를 제공할 수 있을 것으로 생각한다.
2. 공간 빅데이터
공간정보 분야에서 원격탐사 영상, 항공사진, 행정구역별 통계자료, 도로망 데이터, 토지 피복이나 토지이용도와 같은 대용량의 데이터들은 기존에도 존재해왔다. 그러나 최근 약 20여 년 사이에 기존에 상상하지 못했던 다양한 유형의 공간 빅데이터들이 수집되고 있다. 스마트폰의 사용이 일상화되면서 스마트폰에 내장된 GPS(Global Positioning System)2)2) 센서를 통해 다양한 정보가 위치기반으로 수집될 수 있게 되었고, 소셜미디어의 활용이 일상화되면서 개인들은 본인이 느끼는 감성을 친구 및 동료와 공유하고 있다. 택시, 버스 등에 GPS 센서의 부착은 버스나 택시가 언제 도착할지 시민들에게 알려주는 중요한 정보이면서 한편으로는 GPS 궤적의 분석을 통해 교통혼잡, 교통예측, 신호예측, 교통권 분석 등에 활용될 수 있게 되었다. 교통안전, 방범, 방재 등을 위해 설치한 CCTV(Closed Circuit Television)의 실시간으로 생성되는 자료원으로부터 지역 특성분석, 안전분석, 유동인구 분석 등에 활용될 수 있게 되었다. 즉 우리가 전통적으로 생각하고 있던 공간정보 외에도 위치에 기반하여 생성되는 다양한 유형의 대용량 데이터들이 있으며, 이들 데이터가 위치를 기반으로 분석되면서 더 많은 가치를 생성해내고, 활용 가능성을 확대하고 있다. Liu et al.(2015)는 원격탐사 영상(remote sensing)과는 상반되는 개념으로 “소셜센싱(social sensing)”이라는 개념을 언급하였는데, 소셜센싱은 차량궤적 데이터, 소셜미디어 데이터, 핸드폰 기지국 데이터, 스마트카드 내역, 위치기반 체크인 등 대규모 공간데이터가 인간 활동의 역동성과 사회경제적 다양성을 나타낼 수 있으며, 이를 통해 도시의 물리적, 사회경제적 환경을 더 잘 이해할 기회를 가져다준다고 언급하면서 이와 관련된 데이터와 접근법을 나타내는 용어로 사용하였다. 우리가 전통적으로 생각하고 있던 공간정보 외에도 위치에 기반하여 생성되는 다양한 유형의 대용량 데이터들이 있으며, 이들 데이터가 위치기반으로 분석되면서 더 많은 의미분석과 활용 가능성을 확대하고 있다. 공간 빅데이터와 관련하여 자료유형별로 활용이 가능한 데이터를 살펴보면 아래와 같다.
1) 원격탐사 영상, 항공사진, 드론, CCTV 영상
공간정보 분야에서 원격탐사 영상은 기상관측, 국토 모니터링 등에 활용됐지만 최근 이미지 자료를 처리하는 딥러닝 기술이 발전하면서, 재난재해, 환경, 해양, 산림, 농림 등 다양한 영역에서 원격탐사 영상의 활용 가능성이 확대되고 있으며 이에 맞추어 특수목적을 위한 인공위성과 소형위성의 개발이 박차를 가하고 있다. 드론은 조종사가 직접 탑승하지 않고, 지상에서 무선으로 조종하여 사전 프로그램된 경로에 따라 자동 또는 반자동으로 날아가는 항공기다. 공간정보 영역에서 무인 비행 장치는 소형 경량의 기체에 저가의 항법장치와 카메라를 장착하여 후처리 방식으로 지상의 공간정보를 신속하게 취득하는 목적으로 활용되었다. 하지만 최근에는 공간정보 취득이나 제작 외에도 열적외선 카메라(Thermal IR Camera), 소형 라이다(Lidar) 등을 탑재하여 농업 및 작황 조사, 고고학 분야, 연안 침식 및 습지 모니터링, 측량 및 지적 분야, 산림 현황조사, 재난재해 모니터링 등에 활용하고 있다(김석구, 2017).
CCTV는 비디오 감시장치(Video Surveillance)로도 알려져 있으며, 비디오카메라를 이용해 특정된 장소의 한정된 모니터로 신호를 전송하는 방법으로 흔히 위반차량 단속, 안전방범 등 감시 카메라에 사용되고 있다. 지방자치단체의 CCTV 설치는 2008년 157, 197대에서 2021년 1,458,465대로 해마다 평균 약 21.9%씩 증가하고 있으며, 방범, 어린이 보호구역, 공원・놀이터, 쓰레기 무단투기, 시설안전・화재 예방, 교통단속, 교통정보 수집・분석 등을 목적으로 설치되고 있다. 최근 CCTV는 단순한 영상정보만 활용하던 방식에서 특정 소리감지, 근접인식, 실시간 객체 분석 및 현장과의 의사소통 등을 활용하는 지능형 CCTV로 발전하고 있다. 지능형 CCTV를 통해 동적 객체에 대한 탐지, 추적을 통한 객체 인식, 객체의 향후 움직임이나 행위 예측을 통한 유사시 대비와 관련된 연구가 진행되고 있으며, 최근에는 빅 데이터, 영상처리, 인공지능 기술을 융합하여 이동 중인 개인이나 군중과 같은 객체의 전체적인 상황을 탐지하고 분석하는 기술로 발전하고 있다(박서희・전준철, 2017).
2) 거리뷰 영상(street view image)
거리뷰 영상은 인터넷 포털기업들의 지도 서비스 중에 하나로 2007년 구글이 세계의 여러 길과 장소를 360도 카메라로 찍어 볼 수 있게 해준 서비스로부터 시작되었다. 구글 스트리트뷰는 동일지역 재촬영 시기가 정확하게 정해져 있지는 않지만 보통 2~3년마다 재촬영하며 우리나라에서도 네이버 거리뷰, 카카오 로드뷰의 이름으로 서비스를 하고 있다. 거리뷰 영상은 각 포털사이트의 API(Application Program Interface)를 통해 크롤링(crawling)하여 사용할 수 있다.
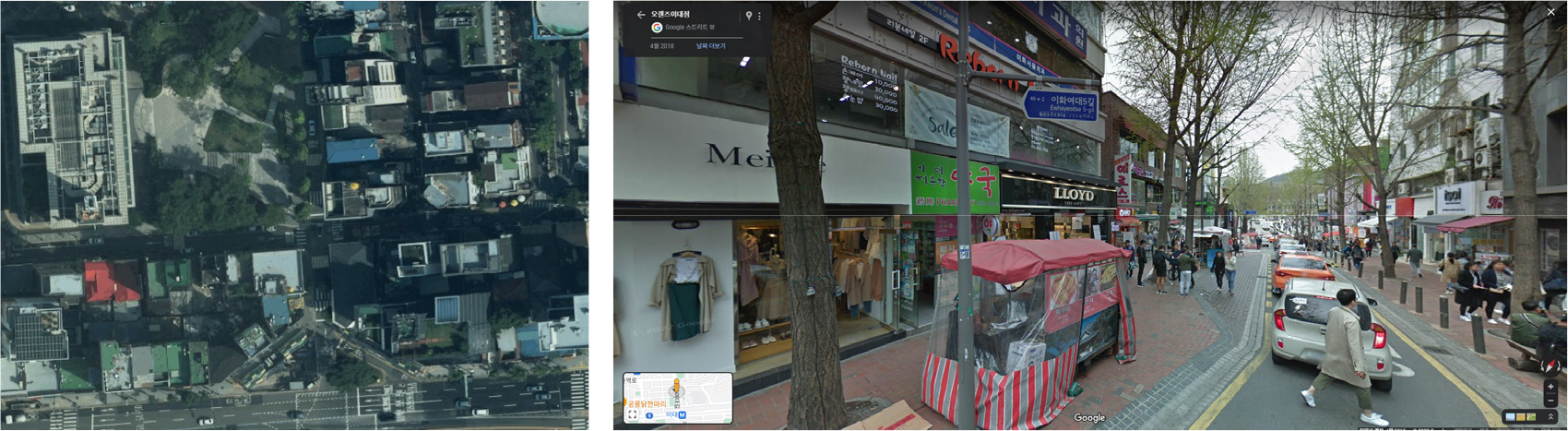
거리 영상은 도시 도로 네트워크를 따라 촬영되는 영상으로 인간의 시각과 비슷한 관점에서 도시 거리의 프로파일을 보여주며 도시의 물리적 환경을 상세히 나타내고 있어 도시환경을 관찰하고 이해하는데 새로운 기회를 제공하는 것으로 평가되고 있다. 거리 영상은 위성이나 항공사진과 같이 하늘에서 수직적으로 촬영한 영상이 아니라 사람의 관점에서 촬영한 영상이기 때문에(그림 1), 해외에서는 도시기반 시설 매핑, 도시구조 및 도시형태 분석, 도시의 녹색지수 분석, 도시 건조환경과 주민 건강과의 상관성 분석, 도시교통과 이동성, 보행환경, 사회경제적 특성, 도시에 대한 인식 등 도시의 건조환경을 평가하는 다양한 연구에 활용되고 있다(Law and Neira, 2019; Biljecki and Ito, 2021).
3) 택시, 버스, 개인의 이동궤적데이터
궤적(trajectory)은 지리적 공간에서 움직이는 물체의 이동을 시간 순서에 따라 나타낸 것으로 일반적으로 궤적을 이루는 각 포인트는 지리적 좌표와 시간 정보로 구성되어 있다. 최근 GPS와 관련된 위치 수집 기술의 발전과 스마트폰과 같은 GPS를 탑재한 디바이스의 폭발적인 증가로 사람, 차량, 선박, 항공체와 같은 움직이는 물체의 지리적 위치에 대한 엄청난 양의 데이터가 실시간으로 수집되고 있다.
궤적데이터는 이동체별로 일정 시간 간격으로 데이터가 수집되는 형태가 있고, 전처리를 통해 궤적의 형태로 구축 가능한 데이터가 있다. 사람이나 차량, 택시 등 GPS 수신장치로부터 수집되는 데이터는 명확한 궤적데이터라 할 수 있으며, 스마트카드 데이터, 센서 데이터, 모바일 기지국 데이터, SNS(Social Networking Service) 데이터 등은 전처리를 통해 궤적데이터로 생성할 수 있다. 스마트카드 데이터나 SNS 데이터의 경우 기록에 담긴 데이터를 ID 별로 처리하여 궤적을 형성할 수 있고, 센서 데이터나 모바일 기지국 데이터의 경우 개인 ID 별 처리는 불가능하지만 세밀한 공간 단위로 구축되기 때문에 이를 가공하여 볼륨을 추정하는 것이 가능하다. 궤적데이터는 교통, 도시계획, 생활양식 분석, 입지분석 등 다양한 분야에서 활용할 수 있다.
4) 소셜미디어 데이터
소셜미디어 데이터는 사람들이 온라인에서 자발적으로 생성하는 데이터이다. 모바일 기기의 확산으로 사용자들은 언제 어디서든 웹 서비스에 접근할 수 있고 이를 통해 자신의 다양한 생각이나 의견을 공유하고 게시할 수 있다. 소셜미디어 서비스를 통해 방대한 양의 데이터가 발생하고 있어 이를 통해 유의미한 정보를 찾아내고자 하는 노력도 증가하고 있다. 소셜미디어 데이터는 자발적으로 표현되고 실시간으로 확보 가능한 정보라는 점 때문에 기존의 인위적인 실험 환경이나 구조화된 설문 방식을 보완할 새로운 연구대상으로 관심을 끌고 있다(임광혁, 2017). 소셜미디어 데이터의 경우 각 소셜미디어 사이트의 API를 통해 데이터를 크롤링하여 사용할 수 있다.
공간정보 분야에서도 재난에 대한 전조 감지나 재난지역의 구조, 사회적 이슈에 대한 지역적 특성분석, 관광 마케팅 등 활용사례가 다수 존재한다. 소셜미디어 데이터에 대한 분석은 기존에는 대부분 텍스트를 중심으로 한 자연어처리, 감성 분석, 이슈탐지, 이슈 모니터링 등이 주를 이루었다면 최근에는 사진이나 동영상 등의 공유가 활발해지면서 이미지 자료를 분석하거나 SNS에 게시된 사진, 텍스트, 위치정보를 함께 모델링하는 분야로 발전하고 있다.
5) 사물인터넷(IoT: Internet of Things) 데이터
사물인터넷은 사람, 사물, 공간, 데이터 등 모든 것이 인터넷으로 서로 연결돼 다양한 정보가 생성・수집・공유・활용되는 초연결 인터넷을 일컫는다. 기술적 관점에서 사물인터넷 기술은 크게 센싱기술과 네트워크 기술, 인터페이스기술로 구성된다. 센싱기술은 다양한 센서를 이용해 온도와 습도, 열, 가스, 조도와 초음파 등의 변동요소를 원격으로 감지하고 분석한다. 아울러 각 변동요소의 위치와 움직임을 추적해 주위 환경으로부터 여러 가지 정보를 얻을 수 있게 해준다. 네트워킹 기술은 유・무선망을 통해 분산된 변동요소들을 서로 연결한다. 인터페이스기술은 사물인터넷의 구성요소를 여러 응용서비스와 연동시켜 효용 가치를 높이는 역할을 한다.
사물인터넷 서비스는 공공부문과 민간부문을 망라해 모두 그 영역을 급속하게 확장하고 있으며, 공공영역에서는 교통운영 효율화, 주차 효율화, 대기오염 완화, 효율적인 에너지 활용 등 도시문제 해결을 위해 적극적으로 활용되고 있다. 현재 국가적 차원에서 많은 관심을 기울이고 있는 디지털 트윈의 많은 서비스가 사물인터넷 서비스와 연계되어 있다. 정적인 공간정보와 동적인 사물인터넷 데이터를 융합하여 분석하면 공간상황을 인지, 예측할 수 있는 지능형 공간구축이 가능할 것으로 예견된다(이용준, 2015). 실제로 서울시에서는 2020년 4월부터 서울시 전역에 걸쳐 설치된 약 1000개 이상의 사물인터넷 센서를 통해 실시간으로 수집되는 환경정보(초미세먼지, 미세먼지, 소음 등)를 2분 단위로 처리하여 서울 열린 데이터 광장 사이트를 통해 공개하고 있으며, 이 외에 스마트 보안등, 스마트 횡단보도, 공유주차장 측정정보, 공공자전거 대여 이력 정보 등을 공개하고 있다(홍상연 등, 2021).
3. 인공지능 기술
1) 인공지능 개요
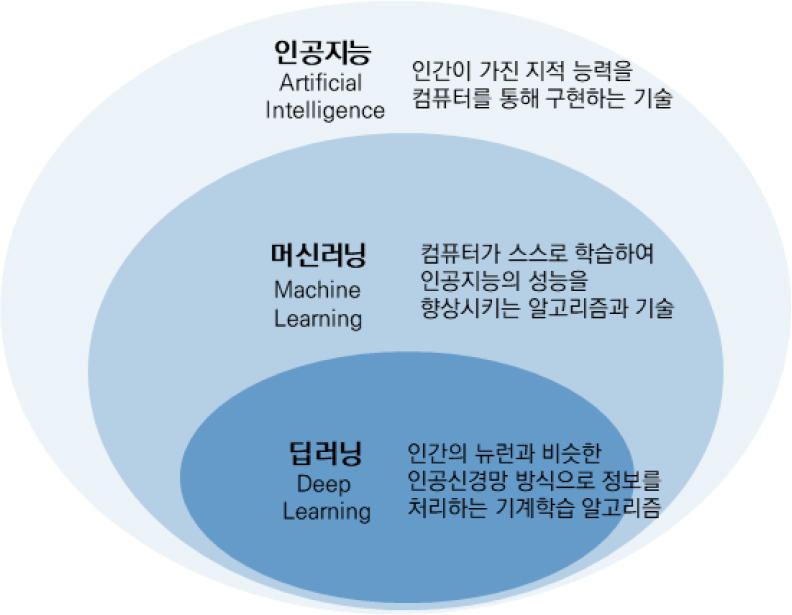
인공지능은 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터시스템을 만드는 기술이다. 인공지능, 머신러닝(machine learning), 딥러닝이 혼용되어 사용되기는 하지만 인공지능은 가장 넓은 개념이며, 인공지능을 구현하는 대표적인 방법의 하나가 머신러닝이며, 딥러닝은 머신러닝의 여러 방법의 하나다(그림 2).
머신러닝은 컴퓨터 프로그램이 알고리즘을 사용하여 데이터에서 패턴을 찾는 인공지능 어플리케이션이다. 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야라 할 수 있다. 머신러닝은 지도학습(supervised learning), 비지도 학습(unsupervised learning), 강화학습(reinforced learning)의 세종류로 나눠볼 수 있다. 지도학습은 입력값과 결괏값(정답 레이블)을 함께 주고 학습을 시키는 방법으로 분류, 회귀 등이 여기에 속한다. 비지도 학습은 결괏값 없이 입력값만 주고 학습시키는 방법으로, 데이터의 차원을 축소하거나 속성에 따라 데이터를 클러스터링하는 방법이 여기에 속한다. 강화학습은 결괏값이 아닌 어떤 일을 잘했을 때 보상(reward)을 주는 방식으로 행동(action)이 최선인지를 학습시킨다. 로봇, 게임 및 내비게이션 등에 이용되며, 일정한 시간 내에 예상되는 보상을 극대화할 수 있는 동작을 선택하도록 한다.
딥러닝은 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘으로 기존의 머신러닝 알고리즘으로 다루기 어려웠던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목받고 있다. 인공지능 발전사에서 두 번째 AI 겨울 동안에도 1998년 얀 르쿤은 신경망 모델을 만들어 손글씨 숫자 인식에 성공하였으며, 이 신경망 이름을 르넷(LeNet-5)이라고 하였는데, 이는 최초의 합성곱신경망(CNN: Convolutional Neural Network)으로 딥러닝을 배울 때 입문자가 가장 처음 접하는 자료가 되고 있다. 2012년에는 제프리 힌턴의 팀이 이미지 분류 대회에서 기존의 머신러닝 방법을 누르고 압도적인 성능으로 우승하였는데, 힌턴이 사용한 합성곱 신경망 모델의 이름이 알렉스넷(AlexNet)이다. 이후 이미지 분류작업에는 합성곱 신경망이 널리 사용되기 시작하였으며 AlexNet을 시작으로, VGGNet, GoogleNet, ResNet, DenseNet, MobileNet, HRNet 등의 합성곱 신경망 모델이 빠르게 개발되었다. 이후 이미지 분류뿐 아니라 이미지 내의 객체탐지, 이미지 내 유사 픽셀 단위로 구분, 시계열 신경망, 훈련데이터 없이 데이터의 특성을 파악하여 신경망을 훈련시키는 모델 등으로 빠르게 발전하고 있다.
2) 딥러닝 모델의 종류
(1) 합성곱 신경망
합성곱 신경망 모델은 딥러닝 모델 발전에 있어 획기적인 전환점을 만든 모델이다. 합성곱 신경망은 인간의 시신경 구조를 모방하여 만든 구조로 이전의 신경망 모델에서 데이터를 입력층에 일차원 행렬 형태로 입력하면서 이미지의 패턴 정보를 잃게 되는 문제점을 해결하였다. 1950년대 허블과 비셀은 고양이의 시각 피질 실험에서 고양이 시야의 한쪽에 자극을 주었더니 전체 뉴런이 아닌 특정 뉴런만이 활성화되는 것을 발견했다. 또한 물체의 형태와 방향에 따라서도 활성화되는 뉴런이 다르며 어떤 뉴런의 경우 저수준 뉴런의 출력을 조합한 복잡한 신호에만 반응한다는 것을 관찰했다. 이 실험을 통해 동물의 시각 피질 안의 뉴런들은 일정 범위 안의 자극에만 활성화되는 ‘근접 수용 영역(local receptive field)’을 가지며 이 수용 영역들이 서로 겹쳐져 전체 시야를 이룬다는 것을 발견했다. 이러한 아이디어에 영향을 받은 얀 르쿤 교수는 인접한 두 층의 노드들이 전부 연결되어있는 인공신경망이 아닌 특정 국소 영역에 속하는 노드들의 연결로 이루어진 인공신경망을 고안해냈고, 이것이 합성곱 신경망이다.
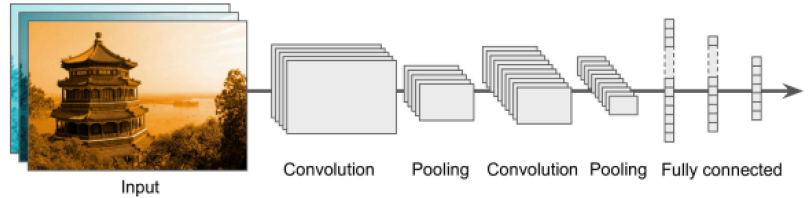
합성곱 신경망은 합성곱 연산과 풀링 연산으로 나뉘는데 합성곱을 활용하여 데이터의 크기를 줄이면서 이미지의 특징을 추출하게 되고, 풀링 과정을 통해 컨볼루션 레이어에서 입력으로 받은 피처맵의 크기를 줄이거나 특정 데이터를 강조하게 된다. 이후 완전 연결 레이어로 연결된 후 이미지 분류(image classification)나 객체탐지(object detection), 시멘틱 세그먼테이션(semantic segmentation)등 목적에 따라 확장될 수 있다(그림 3). 이미지 분류는 이미지가 주어졌을 때 이 이미지가 어떤 사진인지, 어떤 객체를 대표하는지 분류하는 것이다. 일반적으로는 이미지에 하나의 라벨을 부여하지만, 한 이미지에 하나의 특성만 있는 것이 아니므로 한 이미지에 여러 라벨을 부여하는 다중 라벨링을 하기도 한다.
객체탐지는 이미지 내에 특정 객체가 존재하는지를 객체 클래스와 이미지 내에 바운딩박스(BBOX)로 찾아내는 것을 목표로 한다. 객체탐지는 크게 영역기반과 회귀기반으로 구분할 수 있다. 영역기반 객체탐지(region-based)는 객체를 포함할 가능성이 큰 영역을 탐지한 후, 객체를 분류하는 것으로 이 단계 방식(Two-Stage Methods)이라 불린다. 이 카테고리에는 R-CNN, R_FCN, FPN, Retina-Net 등과 같은 알고리즘이 포함된다. 회귀기반 모델은 이미지 픽셀 정보를 바운딩박스와 객체 클래스 확률에 직접 매핑하는 방식으로 단일 단계 방식(Single-Stage Methods)이라고 불리기도 한다. YOLO, SSD, RetinaNet과 같은 알고리즘이 포함된다. 이 단계 방식보다 정확도는 떨어지지만 빠른 처리가 가능해서 실시간 탐지를 요구하는 애플리케이션에 활용된다. 객체탐지는 환경 모니터링, 식생 모니터링, 재난 안전, 도시계획 및 관리, 교통계획 및 관리 등 다양한 영역에서 활용되고 있다.
이미지 세그먼테이션은 이미지 내의 픽셀을 특정 클래스로 분류하는 것으로 결국 이미지를 서로 다른 객체나 클래스로 분류하는 것이며, 픽셀 수준 분류(pixel-level classification)라 할 수 있다. 이미지를 분류하여 다시 이미지의 형태로 결과가 산출되어야 하므로 인코더/디코너(encoder/decoder) 방식의 구조를 갖게 되며, 대표적인 알고리즘으로 U-Net, FCN, SegNet, DeepLab, AdaptSegNet, Fast-SCNN, HANet 등이 있다. 이미지 세그먼테이션은 영상에서 중요 이미지를 찾는 작업, 예를 들면 농업에서 특정 작물 재배지역을 분류하거나, 이미지에서 토지이용이나 토지 피복 분류와 같은 작업에 활용된다. 특히 이러한 알고리즘은 도시화, 사막화, 도시변화나 환경변화와 같은 변화를 탐지하는데에도 활용된다.
(2) 순환신경망(RNN: Recurrent Neural Network)
순환신경망은 입력과 출력을 시퀀스(sequence) 단위로 처리하는 모델로 시퀀스란 연관된 연속의 데이터를 의미하며, 텍스트 분석에서 단어의 나열순서, 시계열 데이터에 시간 단위를 시퀀스로 볼 수 있다. 순환신경망은 현재 시점(t)과 다음 시점(t+1)의 네트워크를 연결하여 시간의 흐름에 따라 변화하는 시계열 데이터를 학습하여 미래를 예측할 수 있다. 주가예측, 시계열 자료 예측, 자율주행차의 이동 경로, 멜로디 예측 등에 활용되며, 문서나 오디오의 자동 번역, 오디오를 텍스트로 변환, 감성 분석, 자동 이미지 캡션 달기 등에도 활용할 수 있다.
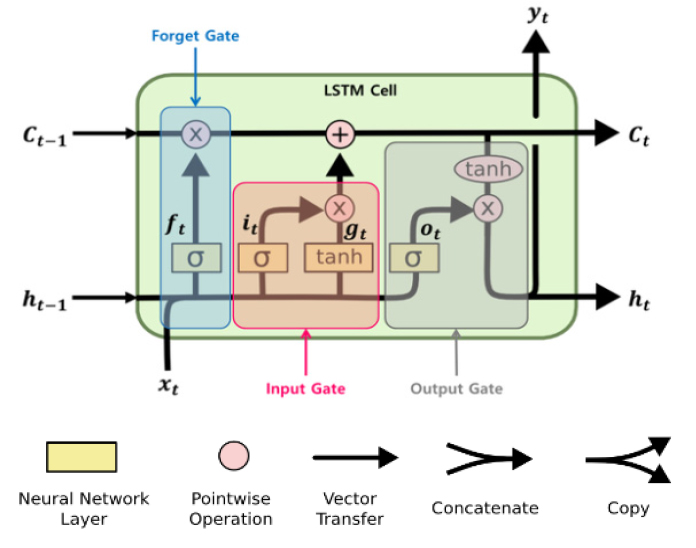
순환신경망이 시퀀스를 갖는 데이터에서 미래를 예측한다는 측면에서는 장점이 있지만 시퀀스의 길이가 길어질수록 즉, 과거 데이터의 입력 위치와 현재 데이터를 출력하는 위치가 멀어질수록 두 정보의 연결이 힘들어진다는 문제가 있다. 이를 장기 의존성(Long-Term Dependency) 문제라 하는데, 알고리즘이 하위층으로 진행됨에 따라 발생하는 기울기 값 소실 문제(vanishing gradient problem)로 인해 발생하며 순환신경망의 성능을 떨어뜨린다. 이러한 문제를 보완하기 위해 순환신경망의 셀을 변형한 것이 LSTM(Long Short-Term Memory) 셀이다(그림 4). LSTM은 과거 데이터의 학습 결과가 현재 데이터의 출력까지 변함없이 전달될 수 있도록 RNN 셀의 구조를 변형한 것이며, 장기의존성 문제 해결은 유지하면서 복잡했던 LSTM의 구조를 간단하게 변경한 모델이 GRU(Gated Recurrent Unit) 모델이다.
(3) 적대적 생성모델(GAN: Generative Adversarial Network)
GAN은 생성모델(generative model)의 한 종류이다. 생성모델은 비지도 학습방법의 하나로 훈련데이터의 확률분포를 추정해서 새로운 데이터를 생성하는 모델이다. 확률분포의 추정방식에 따라 명시적 모델과 암묵적 모델로 나뉘는데 대표적인 암묵적 모델이 적대적 생성신경망(Generative Adversarial Network)이며, 명시적 모델이 변분 오토인코더(VAE: variational autoencoder)이다. GAN은 데이터를 생성하는 생성기(generator)와 데이터를 구별하는 판별기(discriminator)가 경쟁하는 과정을 통해서 데이터를 학습한다. 생성기는 훈련데이터의 분포를 파악하여 훈련데이터와 유사한 가짜 이미지를 생성하고 판별기는 실제 데이터의 확률분포를 추정하여 생성된 이미지가 진짜인지를 판단한다. 판별기는 적대적 손실 값을 제공하여 생성된 이미지가 원본과 유사하도록 한다(그림 5).
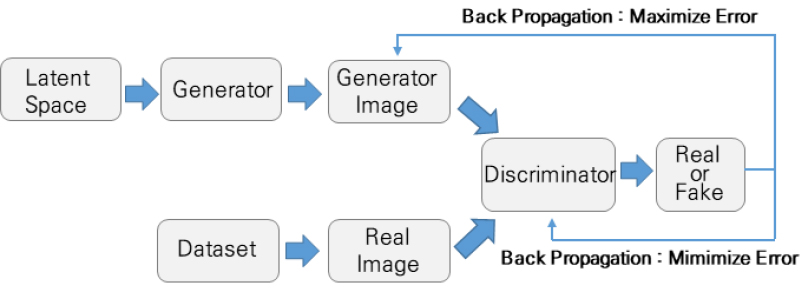
생성기는 다양한 데이터를 생성하는 데 사용할 수 있다. 또한, 확률 분포를 추정하기 때문에 추정된 확률분포를 벗어난 이상 데이터 탐지, 잠재공간에서 데이터 표현학습, 강화학습에서 미래 상태나 행동을 계획할 때도 활용할 수 있다. 예를 들면 이미지 일부가 비어 있을 때 완성된 이미지가 되도록 채워주는 인페인팅 기법, 저해상도 이미지를 고해상도로 바꾸는 이미지 변환, 데이터 증강, 이미지를 다른 스타일의 이미지로 변환하는 이미지 변환 등에 활용된다.
(4) 트랜스포머(Transformer)
트랜스포머는 2017년 구글 AI팀에 의해 발표된 신경망이다(Vaswani et al., 2017). 트랜스포머는 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조로 되어 있다(그림 6). 이를 흔히 시퀀스 모델링(Sequence modelling) 이라고 하는데, 이는 어떠한 시퀀스를 갖는 데이터로부터 또 다른 시퀀스를 갖는 데이터를 생성하는 태스크이다. 예를 들면 번역, 챗봇 등이 있다. 이러한 시퀀스 모델링에는 대부분 순환신경망인 LSTM이나 GRU가 주축으로 사용되었다. 순환신경망 계열의 모델들은 시퀀스 위치에 따라 차례로 입력 데이터를 넣어주어야 하는데, 긴 시퀀스 길이를 가지는 데이터를 처리해야 할 때 메모리와 연산에서 많은 부담이 생기게 된다. 어텐션은 입력 또는 출력 데이터에서 시퀀스 거리에 무관하게 서로 간의 의존성을 모델링 한다. 트랜스포머는 이 어텐션 메커니즘이 핵심을 이룬다.
트랜스포머의 구조는 크게 위치 인코딩, 멀티 헤드 어텐션, 완전 연결레이어로 이루어져 있다. 위치 인코딩으로 위치정보를 파악해서 멀티 헤드 어텐션으로 집중을 하고, 그 결과를 완전 연결 레이어로 학습하는 구조이다. 트랜스포머는 자연어처리 분야에서 순환신경망을 사용하면서 병렬처리가 어려워 연산속도가 느리던 한계를 극복함에 따라 자연어처리 분야에서 높은 퍼포먼스를 보여주었다. 처음에는 자연어 처리 분야에서만 사용되었지만, 이미지 분류 등 컴퓨터 비전 분야까지 다양한 분야에서 활용되고 있다. 최근 큰 관심을 받는 ChatGPT도 트랜스포머 모델에 기반한 것이다.
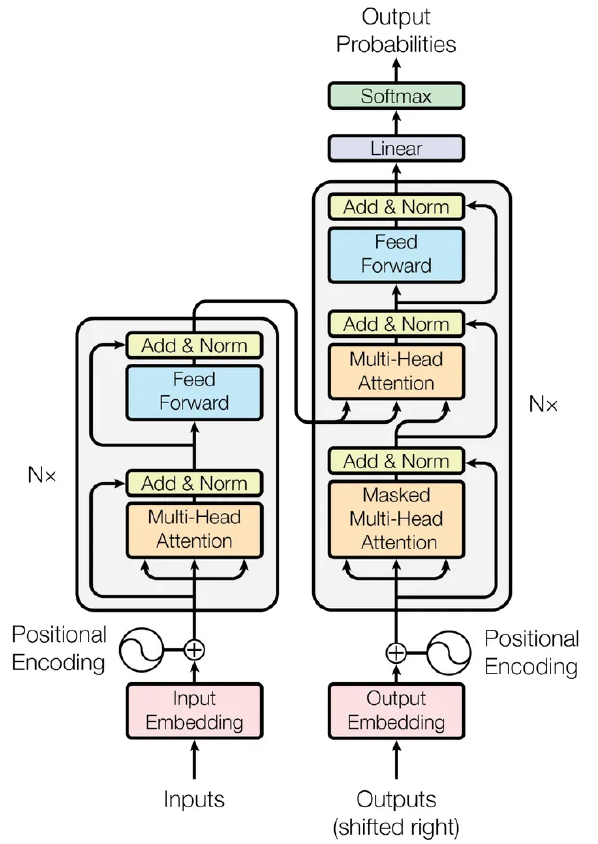
공간정보 분야에서는 합성곱신경망 모델의 합성곱 연산 과정에서 필터를 통해 작은 공간에 주의를 집중하는 구조를 갖는데 트랜스포머는 필터의 크기를 다양하게 결정하면서 합성곱보다 유사하거나 더 나은 성능을 보이는 것으로 연구된 바 있다(Dosovitskiy et al., 2020). 최근에 Vision 트랜스포머(ViTs)는 광란의 20대라 할 만큼 이미지 분류 영역에서 합성곱 신경망을 능가하는 성능을 보이는 것으로 평가되고 있다. 하지만 객체 감지나 시멘틱 세그먼테이션과 같은 보다 까다로운 이미지 분석 작업에서는 합성곱 신경망이 트랜스포머보다 유리한 성능을 보여주고 있는 것으로 평가되고 있다(Liu et al., 2020).
(5) 그래프 신경망(Graph Neural Network)
딥러닝은 최근 몇 년 동안 이미지 분류, 음성 인식 및 자연어 처리영역에서 혁신적인 성과를 보여주었다. 하지만 소셜 네트워크, 지식 그래프, 분자 그래프와 같이 복잡한 연결 관계와 객체 간의 상호 의존성을 분석하는 분야에서는 한계를 드러내었다. 이는 기존의 모델들이 데이터를 정형화된 유클리디안 공간3)3)상에서 분석하기 때문에 관계의 복잡성이 비 유클리디안적 특성을 갖는 데이터를 표현하는 데는 적합하지 않았기 때문이다. 그래프 구조는 관계의 복잡성과 상호 의존성이 비 유클리디안 적이라는 것을 전제로 하기 때문에, 그래프 구조를 갖는 데이터에 대한 분석 수요는 계속 증가하였는데, 그래프 신경망은 그래프 구조를 갖는 데이터에 인공신경망을 적용한 것이다.
그래프는 노드(node)와 그 사이를 연결하는 엣지(edge)로 이루어진 자료구조를 갖는데, 이때 노드는 개개의 자료가 가지고 있는 특징을 나타내며, 엣지는 자료 간의 연관성을 나타낸다. 그래프 신경망의 학습변수는 층별 신경망의 가중치이며, 노드 간 거리 보존을 목적함수로 한다. 그래프 신경망은 노드 분류, 링크 예측, 클러스터링 등에 주로 활용된다.
그래프 신경망은 엣지의 방향이 없고, 그래프가 모두 동종인 단순 그래프 신경망에서 이종 그래프 등 더 복잡한 그래프와 그것에 맞게 변형된 그래프 신경망으로 발전해왔다. 합성곱을 그래프 영역에 적용한 합성곱 그래프 신경망(Convolutional Graph Neural Network), GRU나 LSTM과 같은 순환신경망에서 사용하는 게이트 메커니즘을 전파 단계에 적용해 그래프 신경망 모델의 제약을 줄이고 장기 정보 전파 효과를 향상시킨 순환 그래프 신경망(RecGNN, Recurrent Graph Neural Network), 이웃한 노드들에 각기 다른 가중치를 주어 중요한 이웃과 중요하지 않은 이웃을 구분하여 모델링하는 그래프어텐션 네트워크(GAT, Graph Attention Network), 시공간특성을 모델링할 수 있도록 변형한 시공간 그래프 신경망(STGNN, Spatial-Temporal Graph Neural Network) 등 다양한 모델로 발전되고 있다.
공간정보 분야에서는 다양한 유형의 공간 빅데이터들이 생성되고 있는데 이들 데이터는 공간을 중심으로 서로 연계되며, 지역에 대한 다양한 정보를 포함하고 있으므로 자연스럽게 이들 데이터를 그래프 형태로 연계하여 분석하고자 하는 시도들이 증가하고 있다. 지리학 분야에서는 지역의 특성분석, 도시의 이상 현상이나 이벤트 탐지, 교통계획 수립 및 예측, 사람들의 행동방식 예측 등 활용사례가 증가하고 있다(Li et al., 2022). 그래프 신경망을 활용한 연구에서 유의 깊게 살펴볼 부분은 무엇을 노드와 엣지로 표현하는가와 노드와 엣지의 특성으로 어떤 정보들을 모델링하는가 등이며, 이러한 문제를 해결하기 위해 사용되는 그래프 신경망 모델의 유형은 연구자별로 다양한 접근이 시도되고 있다(표 1). Geng et al.(2019)은 승차 공유서비스의 승객 수요 예측을 위해 STGNN을 사용하였다. 도시지역을 그리드로 나눈 후, 두 그리드 간의 연계성을 인접성, 기능적 유사성, 교통 연계를 나타내는 멀티 그래프로 작성한 후, 지역 전체의 맥락정보를 고려하여 시간대별 특성을 나타낼 수 있는 순환신경망 모델을 사용하고, 이후 지역 간 관련성을 그래프 합성곱신경망을 사용하여 모델링 한 후, 통합된 임베딩을 통해 승객 수요를 예측하였다. Zhou et al.(2020)은 교통사고 예측에 그래프 신경망 모델을 활용하였다. 도시지역을 그리드로 나눈 후, 각 그리드를 노드로, 노드 간에 교통조건의 상관성이 강하면 엣지로 표현하였다. 노드의 속성으로 환경적 특성을 포함했으며, 시간에 따라 그래프를 생성한 후 이를 그래프 합성곱신경망으로 구현하여 숨겨진 특성을 찾을 수 있도록 하고, 이후 순환신경망 기반의 네트워크를 적용하여 교통사고 위험을 예측하였다.
표 1.
그래프 신경망을 활용한 연구에서 노드와 엣지의 표현
| 응용 분야 | 목적(task) | 노드 | 엣지 | 출처 |
| 교통 및 지역 분석 | 교통흐름 예측 | 도로 세그먼트 | 교차점 | Xie et al., 2019 |
| 도로 기능 분류 | 기능 지역 | 도로 연결성 | Wu et al., 2020 | |
| 주차 가능성 예측 | POIs | 도로 연결성 | Zhang et al., 2020b | |
| 환경 모니터링 | 대기 질 추정 | 모니터링 센서 | 근접성 | Wang et al., 2020 |
| 에너지 공급과 소비 | 가스 사용 모니터링 | 레귤레이터 | 파이프라인 | Yi and Park, 2020 |
| 이벤트 및 이상 탐지 | 교통사고 예측 | 도시지역 (그리드) | 근접성 | Zhou et al., 2020 |
| 인간 행동 분석 | 사용자 행위 모델링 | 위치, 객체 | 이벤트 | Wang et al., 2019 |
| 여객 수요 예측 | 도시지역 | 근접성 | Geng et al., 2019 |
(6) 표현학습(Self-supervised representation learning)
딥러닝 분야에서 지도학습 방법으로 모델을 훈련시키기 위해서는 대부분은 라벨링이 잘 된 훈련데이터를 구축하는 것이 필수적이다. 그러나 대량의 라벨링 된 훈련데이터를 구축하는 것은 도전적인 과정이며 딥러닝 모델의 사용을 제한시키는 요소가 되기도 한다. 공간정보 영역에서 이러한 라벨링이 어려운 이유는 데이터 공유 시 개인 프라이버시 문제, 데이터 라벨링에 드는 비용과 시간, 그리고 특정 지역에 대한 지리적 접근의 한계 등에 기인한다. 이러한 한계를 극복하기 위해 전이학습(transfer learning), 반지도 학습(semi- supervised learning), 액티브러닝(active learning)4)4)등의 방법이 제안되었다. 최근에 이런 문제에 대한 해결책으로 자연어처리 및 컴퓨터 비전 영역에서 관심을 받는 분야가 SSRL(self-supervised representation learning)이다(Ericsson et al., 2022).
SSRL모델은 기존의 딥러닝에서 대량의 훈련데이터 셋 구축의 부담을 줄여줄 수 있는 대안으로 많은 관심을 받고 있다. SSRL 모델은 의미론적으로 유사한 인풋은 유사한 표현을 하도록 데이터 표현이 학습되는 것을 목표로 하며, 이는 지도학습 문제를 단순화한다. 즉 SSRL모델은 라벨링 되지 않은 데이터에서 자동화된 방법으로 라벨을 부여하는 방법으로 데이터 표현을 학습하는 문제를 지도학습 문제로 변환한다. 이는 이후 다운스트림 태스크에서 상대적으로 적은 라벨링 된 데이터로도 모델이 잘 훈련될 수 있도록 한다. 공간정보 영역에서는 흔히 표현학습(representation learning)이라고 불린다. 표현학습은 컴퓨터 비전 영역에서 지도학습보다 높은 성능이 도출될 수 있음이 연구된 바 있으며(Goyal et al., 2021), 위성영상분야에서는 이미지생성, 이미지 인 페인팅, 영상의 시퀀스 예측, 영상 분류 등에서 유의미한 성과가 도출되고 있으며(Wang et al., 2022), 위성영상 외에도 공간정보 분야의 지역성 표현, POI 유형 및 개인별 POI 표현, 시간 표현, 사용자 표현, 활동 및 이벤트 표현, 궤적 표현 등 다양한 특징을 분석하는데 성과가 나타나고 있다(Corcoran and Spasić, 2023).
Kim and Kang(2022) 연구에서는 대한민국 방문 관광객의 관광지 이미지 분석을 위해 관광 사진에 대한 사전 분류 카테고리 없이 관광 사진을 자동분류하는 방법을 제안하였다. 해당 연구에서 트립어드바이저(Tripadvisor)에 게시된 리뷰 사진 가운데 한국어를 제외하여 외국인 관광객이 게시한 사진만을 크롤링한 후, Place365 데이터 세트에 사전 훈련된 VGG16Net을 활용하여 각각의 사진을 512차원의 피처(feature) 벡터로 임베딩(embedding)했다. 512차원으로 임베딩된 벡터를 t-SNE를 활용하여 2차원으로 축소한 후, HDBSCAN을 통해 클러스터를 추출하고, 샴 네트워크(siamese network)를 사용하여 카테고리에 포함된 노이즈를 제거하고 사진을 분류하였다. 사진 분류 결과 사전에 사진 분류 카테고리를 생성하지 않아도 관광지별 특징을 반영한 카테고리를 생성할 수 있었고, 적은 양의 데이터 셋으로도 분류 성능을 높일 수 있음을 확인하였다. 이지윤・강영옥(2023) 연구에서는 레이블이 없는 스마트폰 GPS 궤적으로부터 이동 모드를 분류하기 위해 SSRL방법을 사용하였다. 원시데이터로부터 다양한 크기의 세그먼트를 추출하고, 오토인코더(Auto-encoder)와 t-SNE를 활용하여 슬라이딩 윈도우에서 추출된 세그먼트를 벡터로 임베딩하는 SS2Vec(Semantic Segment to Vector) 방법론을 제안하였는데, 이를 통해 이동 모드를 효율적으로 분류할 수 있음을 제시하였다.
4. GeoAI 활용 분야
본 장에서는 GeoAI 활용 분야를 크게 국토 및 환경 모니터링, 도시연구, 감성 분석, 모빌리티 및 예측, 지도학 및 매핑 분야로 구분하여 살펴보고자 한다(표 2). 활용 분야 리뷰에 있어 주로 활용되는 자료원을 고려하여 검토를 진행하였다. 국토 모니터링에 활용되는 자료는 대부분 항공사진, 위성영상 등이며, 도시연구에는 거리뷰 영상, 감성 분석에는 SNS 데이터를 활용한 사례를 중점적으로 분석하였다. 하지만 이들 분류가 서로 완벽하게 배타적이지는 않고, 일부 중복되는 부분이 있다.
표 2.
GeoAI 활용 분야별 딥러닝 모델
1) 국토 및 환경 모니터링
2010년 중반 이후 컴퓨터 비전 분야 딥러닝 기술이 영상자료 분석에 빠르게 접목되면서 토지 피복 분류(조원호 등, 2019; 이성혁・이명진, 2020; Kumar, et al., 2021), 식생 분석(성선경 등, 2021; 신형섭 등, 2021; 장광민, 2021), 재난 탐지(박성욱 등, 2018; 서준호・양병윤, 2022; 이민재 등, 2022; 차성은 등, 2022), 환경오염 모니터링(김나경 등, 2021; 김흥민 등, 2022), 공간객체 추출(이대건 등, 2018; 심승보 등, 2019; 최윤수 등, 2019) 등 다양한 분야에 활용되고 있다. 특히 드론 촬영이 가능해지면서 기존의 원격탐사나 항공 영상이 갖는 시간적 공간적 제약성을 넘어 필요한 시기에 원하는 영상을 얻을 수 있는 환경이 만들어지면서 영상 분야에 딥러닝 기술이 더욱 빠르게 확대되는 추세이다.
원격탐사 영상을 활용한 대표적 활용사례는 토지 피복 분류이다(이성혁・이명진, 2020; Kumar et al., 2021). 원격탐사 데이터는 넓은 지역의 정보를 신속하게 추출할 수 있어 광범위한 지역의 토지 피복 분류에 적합하다. 그러나 자료마다 공간 해상도, 분광 해상도가 다르고, 연구자의 데이터 처리방법 차이로 인해 정확한 결과를 도출하는 데 어려움을 겪기도 하는데, 딥러닝 모델을 통해 더욱 높은 정확도 및 정밀도를 달성하는 것으로 나타났다. 토지 피복 분류에 전통적인 분류기법, 기계학습, 딥러닝 모델을 적용하여 성능을 비교한 결과 다른 기법에 비해 딥러닝 기법에 따른 분류정확도가 높게 나타났으며(Zhang et al. 2021), 해외에 서 다중분광 및 초분광 영상에 딥러닝 기법을 적용한 토지피복 연구는 2015년 이후 매년 두 배 이상씩 증가하고 있고(Vali et al., 2020), 국내연구에서도 원격탐사 영상의 활용 분야를 보면 토지 피복과 관련된 연구가 가장 많다(이창희 등, 2021).
기존에 작물재해 현황 파악은 현장 조사나 전수조사를 통해 이뤄졌는데 이에는 막대한 예산과 인력이 소요되는 한계가 있다. 농업 분야에 딥러닝 기술의 적용은 병충해 탐지, 재배작물 분류, 수계 확인, 잡초 확인, 수확량 예측, 과수 개수 확인 등 다양한 영역에서 이뤄지고 있다(Altalak et al., 2022). 원격탐사 영상에 딥러닝 모델을 적용함으로써 작황 변동 상황 관측 및 예측, 농업재해 대응 등이 가능할 것으로 예견된다. 재해 지역은 사람이 접근하기 어려워서 인적 자원을 투입하지 않아도 매핑이 가능한 원격탐사의 활용도와 가치가 높다. 딥러닝은 산사태 피해지 탐지, 태풍 피해 분석, 지진에 의한 건물 피해 탐지, 산불에 따른 피해 규모 추정(조원호・박기호, 2022; 차성은 등, 2022) 등에 활용되고 있으며, 최근에는 피해가 난 지역에 대한 분석뿐 아니라 드론을 활용한 감시 및 대응으로까지 발전하고 있다(이민재 등, 2022).
영상에 존재하는 객체탐지는 다양한 목적에 활용될 수 있다. 예를 들면 항공사진에서 건물을 추출하여 정보를 갱신하거나, 불법건축물을 추출하여 단속업무의 효율성을 높일 수 있다. 환경오염의 원인이 되는 해양쓰레기, 야적퇴비 등도 정확한 실태조사 및 관리를 할 수 있다. 객체탐지에는 Mask R-CNN, SSD, YOLO 등의 객체탐지 딥러닝 네트워크가 주로 사용되었으나, U-Net, HRNetV2, ResNet 등 의미론적 분할에 이용되는 딥러닝 네트워크도 활용되고 있다.
변화탐지는 두 개 이상의 이미지에서 달라진 부분을 찾아내는 과정이다. 토지이용이나 토지 피복 변화, 사막의 확장, 재해 피해지역 분석, 도시변화 탐지 등 매우 중요한 의미가 있다. 합성곱신경망 모델을 활용한 변화탐지는 Faster R-CNN(Ren et al., 2015; Wang et al., 2018)과 같이 객체탐지기법을 사용하거나 U-Net과 같은 시멘틱세그먼테이션 기법을 사용하였는데 최근에는 CNN과 LSTM의 장점을 혼합한 변화탐지 네트워크(송아람 등, 2019; Khusni et al., 2020; Mou et al., 2019; Sefrin et al., 2021)들이 개발되고 있다.
2) 도시연구
최근 도시연구에 활용되는 대표적인 자료는 거리 영상이라 할 수 있다. 원격탐사 영상을 활용하여 도시확산, 도시녹지 변화 등을 분석하는 것이 가능하지만, 거리 영상자료는 인간의 관점에서 도시의 세세한 특성을 프로파일링하여 나타낼 수 있으며, 인간의 활동이 물리적 공간과 상호작용한 결과로 나타나는 것을 파악할 수 있으므로 도시의 다양한 특성을 분석하는 데 활용된다(Biljecki and Ito, 2021; Li and Hsu, 2022; Zhang et al., 2019a). 거리 영상의 분석에는 시멘틱세그먼테이션 알고리즘, 객체탐지 알고리즘 등이 사용되고 있다.
거리 영상을 활용한 도시연구 연구로 개개 건물을 매핑하여 건물의 유형, 상태, 기능 등을 추정하거나(Kang et al., 2018; Gonzalez et al., 2020; Laupheimer et al., 2018; Yu et al., 2020) 건물의 그래비티 탐색(Novack et al., 2020; Tokuda et al., 2019), 거리 영상에서 탐지되는 도로를 추출하여 도로표면의 종류, 도로의 관리상태, 도로파손 여부를 확인하고(Zhang et al., 2020c; Chacra and Zelek, 2018), 국가 기본도에서 탐지되지 않는 교통표지판이나 신호등(Campbell et al., 2019; Nassar and Lefevre, 2019; Lu et al., 2018), 가로등(Ao et al., 2019), 나무 수종(Chen et al., 2020b; Laumer et al., 2020; Li and Yao, 2020; Thirlwell and Arandjelovic, 2020; Xie et al., 2020a) 등을 탐지하는 도시기반 시설물 매핑 관련 연구가 이루어지고 있다.
도시 녹색지수를 분석하는 연구(Cai et al., 2018; Tang et al., 2020)도 다수 이루어졌는데 도시 녹색지수는 도시민의 건강, 열 저감 효과, 보행 등과 관련성이 있는 것으로 확인되고 있으며, 녹색지수와 녹색환경의 접근성 및 사회경제적 형평성 연구(Ye et al., 2019a; Chen et al., 2020a) 도 이루어졌다. 또한, 거리환경은 건강 및 웰빙과 밀접한 관련성이 있음이 알려지면서 Nguyen et al.(2018) 연구에서는 녹색지수, 보행환경의 대리지표로 횡단 보도, 빌딩 타입을 우편 구역 수준으로 분석하여 녹색지수와 횡단 보도가 많은 곳은 비만이 적음을 밝혔으며, Keralis et al.(2020)의 연구에서는 416개 도시, 3100만 장의 거리 영상을 이용하여 물리적 무질서를 나타내는 밖으로 노출된 전선, 도시발달이 낮음을 나타내는 일 차선 도로가 건강과 관련성이 있는지를 분석하였는데, 전선이 많은 곳에 무질서하고, 정신적 및 육체적 스트레스가 많고, 식습관 관련 질병이 많음을 밝히기도 하였다. 근린환경의 무질서를 나타내는 요소로 낙서, 버려진 차, 관리되지 않은 건물들이 건강과 관련이 있음을 밝히는 여러 연구가 이루어졌다(Kang et al., 2020). 거리 영상을 활용하여 가로의 수준을 평가하는 연구도 이루어졌는데 예를 들면 가로단위로 옥외에 얼마나 그늘이 제공되는지(Li et al., 2018a), 혹은 가로환경의 질이 어느 정도인지를 평가하는 연구(Schootman et al., 2020; Gustat et al., 2020) 도 이루어졌다. 또한, 도시 내 교통 및 모빌리티와 관련된 다수의 연구도 이루어졌는데 특히 교통안전과 관련하여 보행자 사고지점 데이터를 구축한 후 사고지점과 도로상황을 분석하고 사고 다발지역의 특성을 분석하는 연구(Hu et al., 2020) 도 이루어졌다.
최근 보행환경은 녹색 교통수단으로 도시민의 건강증진, 친환경 교통수단 등 다양한 측면에서 긍정적 효과가 있는 것으로 밝혀지고 있는데 기존에 대부분의 보행환경 연구가 설문 조사나 일부 사례지역을 대상으로 현장 조사를 통해 보행환경을 분석하였다면 거리 영상을 활용하여 보행환경을 분석하는 연구들도 이루어지고 있다(Blečić et al,, 2018; Nagata et al., 2020; Bartzokas-Tsiompras et al., 2020). Kang et al.(2023)은 전주시를 대상으로 거리 영상기반 물리적 보행환경과 사람들이 심리적으로 보행하기 좋다고 평가하는 정성적 보행환경 평가 점수를 예측한 후 상대적으로 물리적 보행환경은 좋지만, 심리적으로 느끼는 정성적 보행환경이 열악한 곳을 보행환경 개선 우선 지역화할 필요가 있다고 제안하였다(박지영 등, 2022; 김지연・강영옥, 2022). 또한, 거리 영상은 지역의 사회경제적 특성을 분석하거나(Sytsma et al., 2021; Dakin et al., 2020; Nesoff et al., 2018; Connealy, 2020), 부동산 가치를 평가하는데에도 사용이 되고 있다(Bin et al., 2020; Kang et al., 2021b;, Law et al., 2020, Zhang and Dong, 2018; Zhao et al., 2018; Ye et al., 2019b; Fu et al., 2019; Chen et al., 2020c).
3) 감성 분석
감성 분석 영역에는 사람들이 정성적으로 느끼는 감성을 분석한다는 의미에서 소셜미디어 데이터 분석과 거리 영상을 활용한 도시환경에 대해 사람들의 인지적 평가 관련 연구를 살펴보았다. SNS 분석의 초기에는 SNS에 게시된 텍스트를 분석하는 연구가 주를 이루었으며, 공간정보영역에서는 이를 지역성이나 지역과 연관 지어 분석하기 위해 거주지를 추정하거나 SNS가 게시된 장소를 추정하는 연구들이 이루어졌다(강애띠・강영옥, 2015; Kim et al., 2016). 특히 재난 분야에서 SNS는 재난에 대한 초기감지, 대응, 구조 활동의 중요한 자료원으로 평가받으면서 소셜미디어 데이터로부터 정보를 추출하는 방법과 관련된 다양한 연구가 진행되었다(Kwon and Kang, 2016; Imran et al., 2015; Said et al., 2019). Kabir and Madria(2019) 연구에서는 트윗(tweet)을 활용하여 텍스트데이터를 분류하고, 위치를 찾아내며, 트윗 분류에 따른 구조 우선순위를 정하는 과정을 딥러닝을 기술을 활용하여 제안한 바 있다. 소셜미디어의 텍스트 분석에 초점을 둔 연구가 있는가 하면 소셜미디어에 포스트 되는 이미지로부터 재난의 유형, 피해 종류, 재난의 심각성 등을 분석하거나(Alam et al., 2020; Nguyen et al., 2017) 소셜미디어의 텍스트와 이미지, 동영상을 멀티모달(multi-modal)로 함께 분석하여 재난의 특성을 분석하고자 하는 연구도 진행되고 있다(Hossain et al., 2022; Mouzannar et al., 2018; Ofli et al., 2020).
소셜미디어 데이터의 가치는 관광영역에서도 크게 주목받고 있다. 사람들은 소셜미디어를 통해 관광 정보를 얻고, 여행 중에는 글이나 사진을 게시하며 공유한다. 이러한 소셜미디어 데이터는 관광지에서의 관광 요소 및 관광객이 관광지에 대해 갖는 이미지를 나타내는 것으로 평가되고 있다. 관광 이미지는 개인 혹은 일련의 사람들이 그들이 살고 있지 않은 장소에 대해 갖게 되는 인상이라 할 수 있는데 이러한 관광 이미지 형성에 있어 기존에는 관광공사와 같은 기관에서 형성하는 이미지가 주요했다면 최근에는 관광객들이 생성하는 사용자 생성 콘텐츠(User Generated Contents, UGC)가 주요한 역할을 하는 것으로 평가되고 있다. 이러한 이유로 최근 관광영역에서는 소셜미디어 데이터를 통해 관광지 이미지를 분석하려는 연구들이 이뤄지고 있다(윤지영・강영옥, 2021; Chen et al., 2020d; Cho et al., 2022; Kim et al., 2020; Zhang et al., 2019b; Zhang et al., 2020a). 강영옥 등(2021)은 관광객이 게시한 사진 분석에는 지역의 독특한 경관을 체계적으로 분석하는 것이 중요하며 이를 위해서는 지역에 맞는 관광 사진 분류 카테고리의 개발, 훈련데이터 셋 구축 및 모델 전이학습이 필요함을 설명하면서 대한민국 방문 관광객의 선호관광지, 관광지별 선호활동 그리고 관광객 대륙별 관광 선호활동의 차이를 분석한 바 있다(강영옥 등, 2021; Cho et al., 2022; Kang et al., 2021a; Kim et al., 2020). 한편 관광객이 게시한 포스트(post)를 관광객별로 분석하면 관광객들의 선호를 분석할 수 있으며 이에 기반하여 관광지의 추천이나 다음 관광지를 예측하는 것도 가능하다(박소연・강영옥, 2021; 박소연 등, 2020; Shafqat and Byun, 2020; Yao et al., 2017) .
SNS의 분석은 SNS가 게시된 위치를 분석하기 위해 전통적으로 사용되었던 커널(kernel) 밀도분석뿐 아니라 밀도기반분석인 DBSCAN(Density Based Spatial Clustering of Application with Noise)방법론이 많이 사용되고 있으며, 텍스트 분석에는 단어마다 시퀀스를 고려한 시계열 데이터 모델링 방법이(이혜진・강영옥, 2020; Lee and Kang, 2021; Kabir and Madria, 2019), 사진 분석에는 합성곱신경망계열의 분석이 이루어졌다(Kang et al., 2021a; cho et al., 2022). 최근에는 공간적 특성, 시간적 특성, 사진 이미지특성을 그래프 노드의 속성으로 임베딩한 후, 연결 강도를 연결선으로 모델링하는 그래프 신경망 방식을 활용하는 연구가 새롭게 대두되고 있다(Bai et al., 2022).
거리 영상 자료는 사람의 관점에서 도시의 세세한 특성을 프로파일링하여 나타내기 때문에 사람들이 근린에 대해 느끼는 다양한 감성을 분석하는데에도 활용되고 있다. 사람들의 경관에 대한 평가, 즉 도시가 아름다운지, 안전한지 등에 대한 평가는 정성적으로 느끼는 감성이며, 항공사진이나 드론과 같은 탑 뷰(top-view)가 아닌 사람의 시각에서 보는 거리뷰 영상을 통해 판단할 수 있다. Dubey et al. (2016)은 전 세계 28개국 56개 도시에서 수집한 110,988개 거리뷰 이미지에 대해 “어느 장소가 더 안전하게, 활기차게, 아름답게, 부유하게, 우울하게, 지루하게 보이십니까?” 하는 6개의 감성에 대한 쌍별 비교 결과를 담은 Place Pulse 2.0 데이터를 활용하여 거리 영상기반 정성평가 점수를 예측하는 샴네트워크5)5)와 랭킹로스(ranking loss)를 결합한 street score-CNN(SS-CNN), ranking SS-CNN(RSS-CNN)을 개발하였다. 이후 여러 연구에서 거리 영상을 활용하여 도시의 아름다움, 활기참 등을 예측하기 위한 연구들이 이루어졌다(Santani et al., 2018; Blečić et al., 2018; Xu et al., 2019;, Min et al., 2019; Guan et al., 2021). PlacePulse 데이터 세트는 상대적으로 거리의 경관이 뚜렷하게 다른 세계 대도시를 비교한 것이기 때문에 경관의 다양성이 많지 않은 중소도시의 미세한 경관 차이도 잘 학습할 수 있는 패치(patch) 구조를 추가한 샴기반 모델을 제안하는 연구도 이루어졌다. 해당 연구에서 연구자들은 전주시를 대상으로 사람들의 보행환경에 대한 정성적 평가를 가로단위로 시각화하여 분석하였으며(김지연・강영옥, 2022; Kang et al., 2023), 보행환경의 인지적 평가에 영향을 미치는 거리환경 인자를 머신러닝 기법을 통해 분석하기도 하였다(이지윤 등, 2022a). 한편 Ilic et al.(2019)은 서로 다른 시기의 거리 영상을 보여주고 젠트리피케이션(gentrification)과 같은 시각적 변화가 있었는지를 예, 아니오로 응답하게 한 자료를 훈련데이터로 구축한 후 샴네크워크를 활용하여 젠트리피케이션 유무를 분석하기도 하였다.
4) 이동궤적 분석 및 예측
차량 이동궤적, 사람들의 이동궤적, 선박운행궤적, 동물들의 이동궤적, 자연현상에서 발생하는 태풍의 궤적 등을 분석하고 의미를 찾는 것은 각종 서비스와 정책 수립에서 중요한 과제이다. 궤적데이터는 교통 분야에서는 교통계획 및 관리, 차량 흐름 분석, 운전자 지원, 택시 경로 추천 및 이상 탐지, 도시계획에서는 생활권이나 기능 지역 분석, 보행량 및 특성분석, 입지분석, 장소추천이나 친구 추천 등의 추천시스템, 생활양식을 분석하거나 궤적의 이상치를 탐지하여 길잃은 노인 탐지 등의 노약자 지원 서비스 등에 활용되고 있다(김지연 등, 2022). 궤적의 다음 위치 예측은 크게 벡터 기반, 머신러닝 기반, 딥러닝 기반의 3가지 방법론으로 구분해 볼 수 있는데, 딥러닝 기반 궤적 예측의 경우 시계열성을 갖고 있으므로 LSTM을 활용하는 연구가 주를 이루고 있으며(Tao et al., 2020), CNN-LSTM 기반의 하이브리드 모델을 사용하기도 한다(Song et al., 2020). 궤적 예측에 있어 기하학적 벡터 단위로 예측을 하는 경우는 드물며 궤적에서 의미 있는 장소를 추출하고 이를 단위로 예측을 하거나(Su and Li, 2020) 연구대상 지역을 그리드 셀(grid cell)이나 지오 해시 그리드(geohash grid)로 나눈 후 이동 객체의 다음 셀을 예측하거나(Ip et al., 2021; Rossi et al., 2021), 차량과 같이 도로상에서 움직이는 물체의 경우 교차로, 도로 세그먼트 등을 중심으로 다음 위치를 예측한다(최성진 등, 2019; Li et al., 2018b).
최근 궤적데이터 분석에서 이동체로부터 발생하는 좌푯값이 아닌 비전을 기반으로 하는 분석이 중요한 연구주제로 대두되고 있다. 특히 이 분야는 자율주행이나 방범 및 교통용 CCTV 등이 보급되면서 지능형 시스템으로 발전하고 있어 딥러닝 모델도 다양하게 발전하고 있다. 비전 기반 예측연구는 사고 위험예측(Manglik et al., 2019), 보행자 궤적 예측(Kosaraju et al., 2019; Alahi et al., 2016), 보행자 행동예측(Gujjar and Vaughan, 2019), 차량궤적 예측(Ding and Shen, 2019), 차량 주행방식 예측(Ding et al., 2019), 장면 예측 등의 분야로 구분해볼 수 있다. 예를 들면 LSTM 모델을 근간으로 하지만 CCTV 내 여러 명의 보행자 간의 상호작용을 구현하기 위한 Social-LSTM 모델, 사람의 행동을 관절의 궤적에 기반하여 예측하는 모델, 보행자 분석에 있어 보행자뿐 아니라 지역적 맥락, 보행자 자세, 주변 차량 정보 등을 동시에 고려하도록 시계열 신경망을 쌓아서 예측하는 모델, 장면예측을 RGB 이미지, 옵티컬 플로우(optical flow)맵으로 예측하는 모델 등 다양한 모델들이 개발되고 실험되고 있다(이지윤 등, 2022b).
이 외에 고정된 수집장치로부터 수집된 데이터를 이용하여 대기 질(Seng et al., 2021) 적설(정영준 등, 2022), 하천 수위(정성호 등, 2018), 지하 수위(박재성 등, 2022), 홍수위(정재원 등, 2021) 등을 예측하거나 1시간 간격의 시간 해상도를 갖는 기상영상을 이용하여 해양수온을 예측(최혜민 등, 2022)하는 연구가 시계열 딥러닝 모델을 활용하여 이루어졌다. 한편 허재 등(2020)의 연구에서는 2013년 1월부터 2018년 3월까지 전국 172곳 태양광 발전소 거래 내역 데이터와 기상청의 기상데이터를 사용하여 LSTM 기반의 태양광 발전량 추정 모델을 학습한 후 GIS를 사용하여 추정된 발전량을 공공 유휴부지인 고속도로 주변부를 대상으로 태양광 발전 적지 탐색을 진행하기도 하였다. IOT 센서 데이터는 고정된 위치에서 시계열 자료가 생성되는 반면, 발생지점이 불규칙하지만, 시공간적 특성을 갖는 데이터를 기반으로 이벤트 발생 예측의 최적 공간 단위를 탐지하기 위한 연구도 이루어졌다. 김동은・강영옥(2019)은 2013년부터 2017년까지 서울시에서 6년간 수집된 불법 주정차 민원데이터를 활용하여 민원 다발지역을 예측하는 연구를 수행하였다. 예측의 시간 단위는 월별 24시간으로 설정한 뒤 시계열 예측은 LSTM 모델을 사용하였으며, 자치구 단위, 토지이용유형 단위, 도로 및 도로 외, 토지이용유형 별 도로와 도로 외 공간으로 단위 지역을 구분한 후 예측 정확도가 가장 높은 공간 단위를 분석하였다. 국내에서 시계열 연구에 LSTM이나 GRU 활용이 대부분이지만 해외에서는 트랜스포머를 사용하는 연구들이 증가하는 추세이다(Zerveas et al., 2021; Liang et al., 2022; Lara-Benitez et al., 2021).
5) 지도학 및 매핑
지도학 분야에서 딥러닝을 적용하여 지도 디자인 변환, 저해상도 영상을 고해상도 영상으로 변환, 지도 일반화와 같은 연구들이 진행되고 있다. 공간정보를 최종 사용자에게 전달하면서 지도디자인은 중요한 요소인데 이러한 영역에서 이미지 스타일 변환에 딥러닝 기술이 접목되면서 유의미한 성과를 보이고 있다. 이미지 스타일 변화와 관련된 알고리즘은 GAN(Goodfellow et al., 2014), StyleGAN(Karras et al., 2019), Pix2Pix(Isola et al., 2017), CycleGAN(Zhu et al., 2017)등 GAN 계열의 딥러닝 모델이 주로 활용되고 있다.
최근에 지도는 벡터 형태로 제작되는 것이 대부분이지만 고지도의 경우 하드카피로 존재하는 경우가 많다. 고지도를 스캐닝하여 현재와 비교하는 것은 다양한 분야에서 활용가능성이 있지만 벡터 데이터를 스캔 된 고지도에 정확하게 맞추는 것은 지도제작방법이나 도법의 차이 등으로 매우 어려운 작업이다. Duan et al.(2020)의 연구에서는 강화학습을 통해 스캐닝한 고지도에 벡터 데이터를 일치시키는 방법을 제안하였다. Feng et al.(2019)의 연구에서는 지도 일반화 작업에 딥러닝 기술을 적용하였다. U-net, residual U-Net, GAN의 3가지 방법으로 다양한 축척에서 건물을 일반화하는 과정을 테스트하였으며, residual U-Net의 성과가 좋게 나왔다. 한편 Landsat 8 and Visible Infrared Imaging Radiometer Suite(VIIRS)의 멀티스펙트럴 이미지에 GAN(Pix2Pix) 모델을 적용하여 야간영상 이미지를 생성하기도 하였다(Huang et al., 2020). Kang et al.(2019)은 벡터 데이터에 Pix2Pix, CycleGAN의 두 가지 GAN 모델을 적용하여 구글 스타일, 오프스트리트맵 스타일, 고전 미술 화풍 스타일의 지도를 구현하였다. Xie et al.(2020b)은 원격탐사 영상에서 작고 상대적으로 조밀하게 분포된 건물 외곽선을 추출하기 위해 YOLO 모델을 변형한 LOcally- COnstrained(LOCO)모델을 제안하였다. 딥러닝 기술이 도입되면서 가짜정보나 위조정보가 만들어질 가능성에 대해서도 우려가 되는 상황이다. Xu and Zhao(2018) 는 딥러닝을 활용하여 어떻게 가짜 영상을 제작할 수 있는지를 구현하면서, 가짜 영상이 만들어지는 것에 대한 경각심이 필요하다는 의견을 제시하기도 하였다.
5. 결론
인공지능 기술의 발전이 기존의 상상을 뛰어넘어 빠른 속도로 발전하고 있다. 2010년대 인공지능 기술이 컴퓨터 비전, 자연어 처리영역에서 인간의 능력을 뛰어넘는 성능을 보여주면서 지리학 및 공간정보 분야에서는 원격탐사 영상을 연구하는 분야에서 이들 기술을 접목하는 연구가 다양하게 이루어졌다. 하지만 최근에 기존에 상상하지 못했던 다양한 정보들이 생성되면서 대규모 공간데이터가 기존에 전혀 예상하지 못했던 지역의 물리적, 사회경제적 환경을 더 잘 이해할 수 있는 기회를 가져오고 있다. 지리학은 공간을 매개로 다양한 정보들이 연계되기 때문에 그 어느 영역보다 다양한 유형의 데이터를 위치기반으로 연계하여 분석함으로써 시너지를 낼 수 있는 분야이다.
다양한 유형의 공간 빅데이터와 인공지능 기술을 접목하여 국토 및 환경, 도시 및 지역 연구, 교통, 재난 안전, 관광 등 다양한 분야에서 지능화된 서비스를 제공할 수 있을 것으로 판단된다. 특히 인공지능 기술의 발전은 이러한 다양한 데이터를 어떻게 분석하고 의미를 도출해낼 수 있을지에 대한 중요한 방법론을 제공한다. 인공지능 기술이 빠르게 발전하고 있지만, 지리학 분야에 인공지능 기술 접목을 위해서는 독창적으로 방법을 찾아야 하는 영역들이 분명히 존재한다. 공간을 어떻게 모델링 할 것인가, 공간적 관계를 모델링할 때 객체의 단위와 관계는 어떻게 표현할 것인가, 지리학 도메인 특성에 맞는 모델의 개발과 융합은 지리학과 공간정보를 다루는 영역에서 연구되어야 할 분야이다.
인공지능 기술의 발전 측면에서는 초창기에 잘 훈련된 데이터 세트, 즉 인공지능을 위한 훈련데이터 셋 구축이 필요했던 시기가 있었던 반면 지금은 그러한 데이터 세트가 충분하지 않아도 성능을 높일 수 있는 비지도 학습, 데이터가 갖는 특징을 학습하여 다운스트림(down stream) 태스크(task)의 성능을 높이는 표현학습, 그리고 객체의 특성만을 분석하는 것이 아니라 객체와 관계 속에서 지능(intelligence)을 찾아내고자 하는 그래프 신경망 등이 빠르게 발전하고 있어, 다양한 영역에서 기존에 해결하지 못했던 문제들을 더 효율적으로 해결할 수 있는 실마리를 제공할 수 있을 것으로 생각된다.
