

1. 서론
2. 선행연구
1) 장래가구추계 방법
2) 소지역 단위 장래가구추계 방법
3. 소지역 단위 장래가구추계 모델링
1) LSTM 모델의 설계
2) 연구 범위 및 데이터
4. LSTM 모델의 예측력 검증 및 추계 결과
1) LSTM 모델의 예측력 검증
2) LSTM 모델을 이용한 장래가구추계 결과(2025~2045년)
4. 결론
1. 서론
현재 우리나라는 전 세계적으로 가장 빠른 속도의 인구 변화를 겪고 있다. 통계청의 인구총조사에 따르면, 한국의 65세 이상의 고령인구는 2023년 기준 19.1%로 2000년 고령화사회(aging society)에 첫 진입 후 고령인구 비율이 가파르게 증가하여 현재는 초고령사회(super-aged society) 진입을 눈앞에 두고 있다. 반면 2023년 합계출산율은 0.721명으로 급격하게 수치가 감소하고 있어 앞으로 인구와 관련한 다양한 사회경제적 문제를 겪을 것으로 예상된다. 우리나라의 실제 인구수는 2023년 기준 5,177만 명으로, 수년 안에 정점을 기록한 후에 감소 추세로 돌아설 것으로 예측되며, 감소 속도는 점점 더 가속화될 것으로 보여진다.
한편 이러한 인구수 변화에도 불구하고 가구수는 빠른 속도로 증가해왔으며, 가구 구조 또한 크게 재편되어왔다. 과거에는 주로 가구 구성이 3・4인 가구 중심으로 이뤄졌다면, 최근에는 1・2인 가구 중심으로 그 주류가 변화되었으며, 가구주의 연령 또한 빠르게 고령화되고 있다. 통계청 장래인구・가구추계에 따르면 가구수는 인구수보다는 오랜기간 동안 증가할 것으로 전망되며, 2039년 2,398만 가구를 정점으로 한 후 이후에는 가구수가 감소할 것으로 예상된다.
가구는 인구의 합으로 구성된 것으로, 인구의 한 부분으로 볼 수도 있지만 그 자체로 분석의 필요성이 존재한다. 가구의 개념을 담은 가구 인구학(household demography)은 1980년대 이후 인구학의 하위 분야로 등장하기 시작하였으며, 전통적인 인구학에서 개별의 인구가 하나의 연구 단위인 것과는 달리 가구 인구학에서는 여러 인구의 조합으로 이뤄진 그룹 형태를 다루고 있다는 점이 큰 차이이다. 인구 변화와 관련된 다양한 과정들은 그 인구가 포함된 가구의 상황에 의존적이며, 특히, 가구 구조가 급격하게 변화하면서 가구에 대한 중요성이 점차 증가하고 있다(Van Imhoff, 1995).
과거에는 혈연 혹은 친족 관계로 구성된 가족(family) (UN, 1958)의 개념이 중요하였으나, 가족은 공동생활 집단으로서 측정이 어려운 경우가 많다는 단점이 존재한다. 한편 가구(household)란 생계 활동을 공동으로 하는 사람들 혹은 사람들의 경제적 단위(UN, 1958)를 의미하는 것으로 최근 혈연이라는 개념이 옅어지고 가족 외의 사람과 함께 거주하는 비중이 점차 증가하면서 가구라는 개념에 대한 중요성과 활용도가 증가하고 있다.
이러한 가구의 개념은 현재 인구총조사와 같은 여러 조사에서 기초적인 조사 단위로서 활용되고 있으며, 국민기초생활수급 혹은 정부의 여러 지원정책을 위한 단위로 활용된다(통계청, 2022). 또한 가구는 주택 산업에서 주택을 구매하는 하나의 소비 단위이자 그 외 기본적인 인간의 생활과 관련된 수도, 전기, 가스 등과 같은 공공 인프라에 대한 수요 단위로 활용될 수 있으며, 자동차, 가구, 가전제품과 같은 소비재에 대한 수요에도 가구는 중요한 단위로 활용된다(이상일, 2012).
이러한 가구의 개념 및 가구 단위의 분석에 대한 중요성은 과거, 현재뿐만 아니라 미래의 변동성에도 중요한 의미를 가질 수 있다. 미래에 대한 측정치 중 추계(projection)는 미래에 대한 일련의 가정들의 수많은 결과로서 과거, 현재의 정보를 기반으로 계산한 추정치(estimate)를 바탕으로 한 결과이다(George et al., 2004). 그러므로 장래가구추계 자료는 발생할 수 있는 미래에 대한 측정치로 실세계의 다양한 영역에서 활용이 가능하다.
국내에서 장래가구추계는 2002년부터 통계청에서 공식통계로 작성하기 시작하였다. 공식적인 가구추계 방식은 가구주율법으로, 전체 인구 중 가구주가 되는 비율을 추계하고, 장래인구추계 결과와 결합하여 장래가구수를 산출하고 있다(통계청, 2020). 이러한 공식적인 장래가구추계 결과는 전국 및 시도 단위까지 발표되고 있으며, 전국 단위를 기준으로 추계 결과를 작성한 후, 시도 단위에 비례적으로 할당하는 방식으로 시도별 추계 결과를 산출하고 있다.
지방자치 시대에 지역의 다양성을 담는 미래계획과 정책 수립이 무척 중요한 상황에서 시도 단위의 장래가구추계의 활용은 한계점이 명확하다. 즉, 이보다 더 작은 지역 단위에서의 미래의 공간적 다양성과 변화를 파악할 수 없기 때문에 지역적 차별성을 반영하는 정책 수립이나 수요 분석에 장래가구추계를 활용하는 것은 불가능한 실정이다. 실제로, 소지역 단위의 추계를 작성하는 데 필요한 기초 자료들이 적합한 수준으로 제공되지 않고 있으며(Wilson et al., 2022), 추계 방법 역시 복잡하여 소지역 단위의 장래추계 연구의 진척이 매우 미비한 상황이다.
과학적이고 체계적인 방법을 통해 적절한 수준의 예측력을 가진 소지역 단위의 장래가구추계가 작성된다면 다양한 인구‧주택 정책 수립뿐만 아니라 도시 내의 인프라, 주택시장 분석, 미래 주택 수요 추정 등에 활용할 수 있는 중요한 기초 자료가 될 것이다.
이러한 맥락에서 본 연구는 소지역 단위의 장래가구추계에 활용할 수 있는 새로운 딥러닝 기반 모델을 제시하고, 모델에 대한 예측력 검토를 통해 서울시 자치구별 가구추계에 대한 실제 적용 가능성을 살펴보고자 한다.
2. 선행연구
1) 장래가구추계 방법
가구는 인구의 집단으로 구성되기 때문에 인구 변화와 중요한 연관성을 가지며, 인구 구조의 변화는 가구 구조에 영향을 미칠 수 밖에 없어 가구추계는 인구와 가구 간의 관계를 잘 고려하는 것이 필요하다. 인구추계 방법의 경우 코호트 요인법(Cohort-component method)이 표준화된 방법으로 알려져 있으나(Smith et al., 2001), 가구추계는 인구추계와 달리 단일의 표준화된 방법이 없어 보이며(이상일, 2012), 국가별 공식통계에서도 다양한 방법들이 활용되고 있다(오진호・윤영규, 2020).
Bell et al.(1995)은 가구추계 방법을 크게 정태적(static) 방법과 동태적(dynamic) 방법으로 구분하였다. 정태적 방법은 여러 시점 간의 인구 분포와 가구 속성을 비교하는 방법으로, 인구 구성비와 비율을 가구수에 할당하는 방식이라면 동태적 방법은 일정기간 동안 발생한 코호트의 변화를 추적하여 가구 상태 간의 변화를 포착하는 방법을 의미한다(오진호・윤영규, 2020; 이상일, 2012; Bell et al., 1995).
이러한 가구추계 방식 중 비교적 널리 사용되는 것은 가구주율법(headship rate method)이다. 대표적인 정태적 방법인 가구주율법은 성, 연령별 추계인구에 해당 집단의 가구주율을 곱하여 전체 가구수를 추계하는 방식으로, 혼인상태별 가구와 주거의 특성을 추가하여 추계할 수 있어 가장 흔히 사용되는 방법이다. 초기 가구주율법은 가구주의 연령별 구조만을 활용하였으나, 여성과 남성의 혼인은 가구 해체와 형성에 영향을 미치기 때문에 점차 가구주의 성별도 동시에 고려하는 형태가 되었다(Mason and Racelis, 1992).
이러한 가구주율법은 한국의 공식적인 장래가구추계에도 활용되는데, 성별, 연령별, 혼인특성별로 가구 형태를 구분하여 추정된 장래인구값에 가구주율을 곱하여 장래가구수를 추정한다. 가구주율법은 기본적으로 인구추계 자료에 가구주율을 계산하여 활용하기 때문에 가구주율을 어떻게 계산하여 가구추계를 하는지에 대한 연구가 주를 이루고 있다. 가구주율 추정방식은 외삽법(extrapolative method)(김형석, 2002; 장영식 등, 1998; United Nations, 1973), 회귀분석법(regression method)(Burch and Skaburskis, 1993; Day, 1996), APC 분석법(Age-Period Cohort method)(곽하영 등, 2018; Givisiez and de Oliveira, 2005) 등 다양한 방식이 활용되어왔다. 가구주율은 비교적 계산 과정과 필요한 자료가 단순하고, 인구 연령 구조 변화와 같은 변수에 민감하기 때문에(이상일, 2012), 급변하는 인구・가구 구조를 가지고 있는 국내에서 특히 적절한 방법으로 알려져 있다(김형석, 2002). 하지만 가구주율법은 인구추계 자료가 우선적으로 필요하다는 점과 국가별로 가구주에 대한 개념의 차이가 있으며, 가구주의 지위가 시간에 따라 변화할 수 있다는 점을 간과한다는 약점이 있다. 따라서 일부에서는 동적 모델을 활용하는 것이 더 적절하다는 주장도 있다(Zeng et al., 1998).
한편 동태적 방식은 특정한 속성에 따라 가구 형태를 먼저 구분한 후, 개인의 지위가 시간이 지남에 따라 변화하는 확률을 이용하여 장래의 가구를 추계하는 방식이다. 대표적으로 전이행렬을 이용한 가구전이법(household transition method)이 있다. 가구전이법은 기본적으로 성, 연령 등으로 구분된 가구의 형태가 다음 시기에 다른 가구 형태로 전이할 확률을 계산하여 적용한다. 실제로 일본의 공식적인 장래가구추계에 가구전이법이 활용되고 있으며(오진호・윤영규, 2002), 일부 국내 연구에서도 가구전이법을 활용하여 가구추계를 시도한 바 있다(이지혜, 2023; 황지은 등, 2011).
2) 소지역 단위 장래가구추계 방법
장래가구추계는 다양한 분야에서 필요성이 있는 자료이나, 여전히 소지역 단위로 작성하는 것은 어려움이 있다. 특히 소지역 단위에서의 추계에 필요한 기초 데이터의 확보에 어려움이 있으며, 작은 단위의 지리적 범위 내에서는 예측 오차가 커져 높은 불확실성을 보이게 된다는 점이 가장 큰 장애물이 되고 있다(Smith et al., 2001). 또한 소지역 단위의 장래가구추계는 소지역 단위 인구추계에 비해 훨씬 더 복잡하기 때문에(Van Imhoff, 1995), 이에 대한 학술적 연구는 거의 이루어지지 않고 있다.
국가 수준에서 시도 단위의 장래가구추계는 국내에서 공식 통계로 발표되고 있으며, 시도 단위에서 가구주율법을 이용한 가구추계 연구들이 일부 진행된 바 있다(김유경, 1995; 이상일, 2012). 가구주율법을 이용한 가구추계의 경우 시도 단위에서 비교적 쉽게 적용이 가능한데, 이는 가구주율 추정 방법에 대한 논의보다 소지역 단위 인구추계 자료의 유무가 더 중요하기 때문이다.
한편 국가 수준의 지역 단위보다 더 작은 소지역 단위의 가구수 추계를 시도한 연구 중 하나는 Ip and McRae(1999)가 있다. 이 연구에서는 기존의 장래가구추계의 방법을 사용하지 않고 소지역 단위로 가구당 평균 인원을 추계하여 전체 가구수를 추정하였으며, 가구당 평균 인원은 지역별 0~19세 사이의 자녀 수, 혼인율, 이혼율을 독립변수로 회귀분석을 통해 도출하였다. 또한, 소지역 추계 자료 작성을 위해 비교적 신뢰도가 높은 국가 단위의 예측에 기초하여 그 경향성을 소지역 단위에 적용하는 간접적인 방법을 택하기도 하는데(Smith et al., 2001), 국가/주 단위 수준에서의 통계로 추계 한 뒤, 하위 지역 단위에서 과거의 가구 특성별 비율을 적용하여 장래가구추계 결과를 할당하는 방식을 이용하기도 한다(Zeng et al., 2010; 2014).
그 외 Hooimeijer and Heida(1994)는 소지역 단위에서 가구추계에 동적 모델을 이용하였다. 네덜란드의 주택시장과 가구수를 연결하여 가구의 주택 점유형태, 연령, 연소득을 유형화하여 총 72개의 거주 유형을 구분하고, 가구의 점유 비율에 대한 국가 단위의 전이행렬을 작성하여 소지역 단위의 가구수 변화를 추계한 바 있다.
이와 같이 소지역 단위에서의 장래가구추계에 대한 필요성에 따라 일부 의미있는 연구들이 진행되었지만 여전히 적절한 방법론에 관한 연구들은 매우 부족한 상황이다. 이는 기존의 가구추계에 활용한 방법들이 상세한 수준의 기초 자료가 요구되는 소지역 단위로 직접 적용하는 데 실제적인 어려움이 있기 때문이다.
가구주율법의 경우 선행적으로 소지역 단위의 인구추계 결과를 필요로 한다는 점이 큰 장애물이며, 동적 모델의 경우 소지역 단위로 전이행렬을 구축할 때 막대한 입력값이 필요하여 실제 구현이 쉽지 않다.
따라서 소지역 단위에서 활용 가능하면서, 기존의 추계 방법들이 가진 단점들을 극복할 수 있는 새로운 소지역 단위 가구추계 방법이 절실히 필요한 시점이다.
본 연구는 소지역 단위의 인구추계 결과에 대한 자료 없이 과거의 인구・가구수 변화 데이터만을 이용하여 소지역 단위의 가구 변화 추계를 시도한다는 점에서 기존의 연구와는 차별되는 접근이라 할 수 있다.
3. 소지역 단위 장래가구추계 모델링
1) LSTM 모델의 설계
앞서 살펴본 것과 같이 기존의 가구추계 방법들을 소지역 단위 추계에 직접적으로 적용하는데에는 여러 가지 한계가 있다. 가장 빈번하게 사용되는 가구주율의 경우 선행적인 소지역 단위의 인구추계 결과가 없으면 적용이 불가능하며, 동적 모델의 경우 소지역별로 전이 확률을 계산해 낼 자료를 확보하는 데 어려움이 있다. 여기에서는 기존의 방법들의 한계를 극복하고, 과거의 가구 구조를 기반으로 소지역 단위의 가구를 추계할 수 있는 새로운 가구추계 방법을 제시하고자 한다.
보다 구체적으로 딥러닝 방법 중 하나인 LSTM(Long- Short Term Memory) 모델을 활용하여 소지역 단위의 장래가구추계를 수행한다. 최근 여러 분야에서 미래 예측을 위해 다양한 인공지능 기법이 활용되고 있으며, 특히 예측의 복잡성이 있는 경우 수많은 변수를 동시에 고려할 수 있다는 것이 인공지능 기법의 큰 장점이다. 그 중 LSTM은 순환신경망(Recurrent Neural Network: RNN) 방법 중 하나이다. 순환신경망이란 여러 개의 데이터가 순서대로 입력될 때 스스로 반복하면서 이전 단계에서 얻은 정보가 지속되도록 하는 모델이다(Olah, 2015). 일반적인 신경망 방법은 이전에 발생했던 사건을 기반으로 이후에 연결되는 사건을 고려하지 못하기 때문에 시계열적으로 연결된 현상을 분석하는데 어려움이 있어 이를 해결하기 위해 순환신경망 방식이 유용하다. 하지만 전달되는 데이터가 길어질수록 과거의 정보가 잊혀지고, 연산이 반복될수록 그래디언트가 소실되는 약점이 있다. LSTM은 이러한 순환신경망의 구조적 특성을 개선하여 보다 긴 의존기간을 필요로 하는 학습을 수행하는 데 이용가능한 장점이 있다(Hochreiter and Schmidhuber, 1997). LSTM 모델은 각 유닛에 일정 시간 동안 정보를 저장하여 장기적인 시간적 의존성과 패턴을 고려하는 것이 가능하도록 하여 시계열 분석에 탁월한 성능을 발휘하는 것으로 알려져 있다(Grossman et al., 2023).
또한 LSTM 모델의 경우 단일 변수를 이용한 단변량 모델 뿐만 아니라 다른 변수를 동시에 고려할 수 있는 다변량 LSTM 모델을 통해 계산이 가능하다. 가구의 경우 인구 변화와 밀접한 관련이 있어 인구 특성을 동시에 고려해야 할 필요가 있으며, 소지역 추계는 특히 공간적 변화를 담을 경우 더 정확한 예측이 가능하기 때문에 다양한 변수를 고려할 수 있는 모델이 필요하다.
소지역 단위 장래가구추계를 위해 구축한 LSTM 기반의 추계 모델 설계 과정은 그림 1과 같다. 본 모델링의 기본 프레임워크는 Grossman et al.(2023)이 호주의 소지역 단위 인구추계를 위해 제시한 모델에 기반하며, 가구추계에 적합한 형태로 변형하여 다변량 LSTM 모델로 구성하였다.
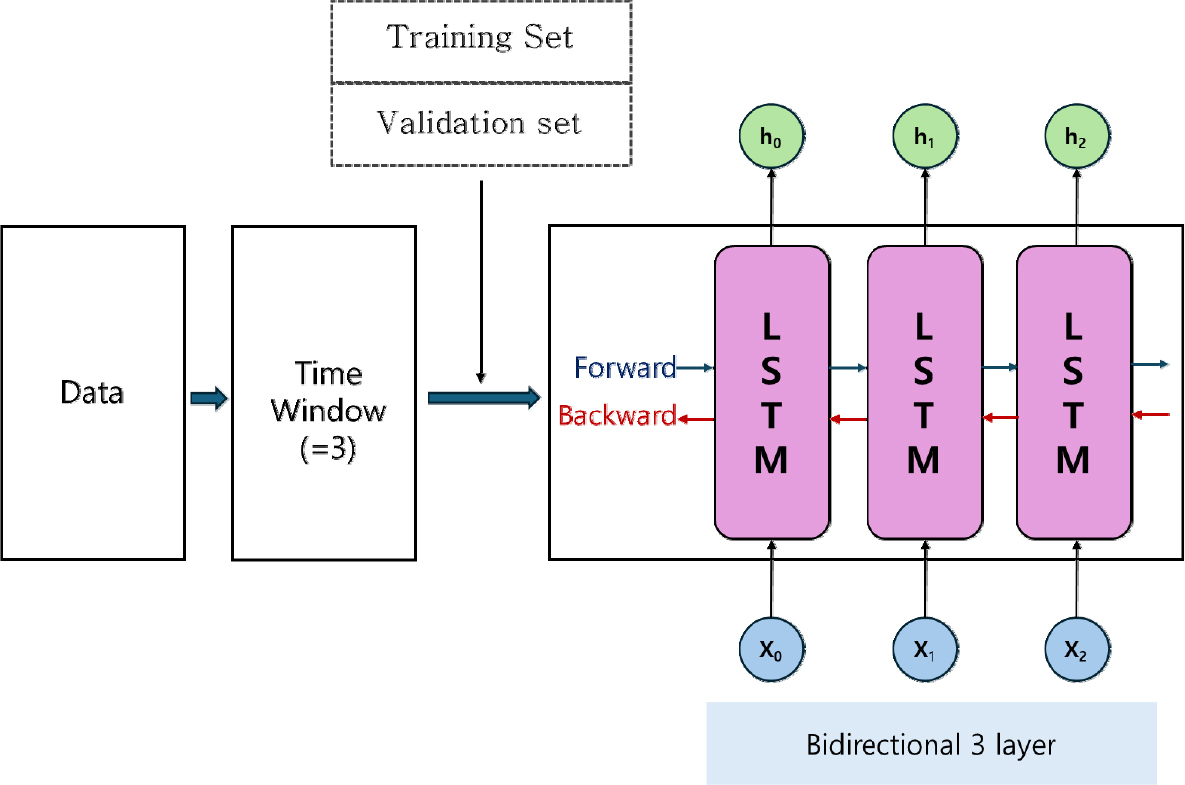
입력 데이터는 과거의 가구 특성별 가구수 데이터로 일관성있게 구축할 수 있는 최대 범위를 활용하였다. 가구 구조의 특성을 반영하기 위하여 가구원수를 1명/2명/3명/4명 이상으로 구분하였고, 가구주의 연령을 20대 이하/30대/40대/50대/60대 이상으로 구분하여 소지역별로 활용하였다. LSTM 모델에 입력하기 위해서는 지도 학습 데이터 변환 과정이 필요하며, 이는 윈도우 슬라이딩을 통해 가능하다. 윈도우의 크기를 이용하여 한 번에 입력되는 데이터의 개수를 결정하고, 이를 이후 값을 예측하는데 활용하기 때문에 윈도우의 적절한 크기를 결정하는 것은 중요하다. 윈도우 슬라이딩을 통해 윈도우 크기를 테스트한 뒤 적절한 크기를 결정해야 하나, 과거 가구수의 시계열 길이가 짧아 3개 초과의 윈도우 크기로는 예측치 산출이 어려워 부득이 3개의 윈도우 크기를 활용하였다.
LSTM 모델의 레이어는 양방향 신경망의 형태로 총 3개로 구성하였다. 일반적으로 많은 레이어를 만들수록 더 복잡한 함수를 계산하는 것이 가능하나, 이것이 항상 더 나은 예측력을 담보하는 것은 아니기 때문에 적절한 수준에서 최적화된 가중치를 찾을 수 있도록 테스트 후 최종 레이어의 수를 결정하였다. 또 한 레이어를 단일 방향으로 구성하는 것보다 양방향으로 구성할 경우 더 많은 시계열에 노출되어 과거의 값이 아닌 미래의 값에 기반으로 한 최적의 가중치를 찾는 것이 가능하기 때문에(Grossman et al., 2023), 최종 양방향의 3개 레이어를 가진 LSTM을 모델을 구축하였다.
해당 LSTM 모델은 훈련 데이터를 이용하여 학습하고, 검증 데이터를 통해 오차율이 가장 낮은 수준의 모델을 작성하도록 구축하였다. 오차가 최소화되도록 만들어주는 알고리즘은 Adam의 최적화 방법을 사용하였다. 오차 수준은 평균 절대 비율 오차(Mean Absolute Percentage Error: MAPE)를 사용하였으며, 여기서 MAPE가 10% 이하가 되는 수준에서 추계 모델을 구성하였다.
본 연구에서 제시하는 LSTM 모델은 다변량 LSTM 모델로서 가구수 데이터와 함께 인구수 변화 및 주거 환경의 공간적 변화(주거용 연면적)를 동시에 고려하고 있다.
LSTM 모델은 Python 3.11.7 64 bit를 이용하여 구현하였으며, 텐서플로우(tensorflow) 2.16.1 버전 라이브러리를 사용하였다.
2) 연구 범위 및 데이터
본 연구의 공간적 범위는 서울특별시이다. 전국의 인구가 지속적으로 증가하고 있었던 것과는 달리 서울은 2000년 이후 지속적으로 인구 감소를 경험하고 있는 도시로, 인구 감소와는 또다른 양상의 가구 변화를 겪고 있는 곳이다. 즉, 20대 청년층의 지속적인 유입과 고령화로 인해 1인 가구가 빠르게 증가하고 있고, 동시에 30~40대 가구가 외곽으로 유출되어 3・4인 중심의 가구는 감소하고 있다. 이처럼 서울은 가구 구조가 가장 급격하게 변화하고 있는 곳으로 가구추계의 필요성이 높은 지역이라 할 수 있다.
본 연구에서 활용한 시간적 범위는 2000~2023년으로 추계의 기준이 되는 연도는 2020년이다. 2000~2020년 가구수는 모델의 학습에 활용되었으며, 2021~2023년 3개년 자료로 LSTM 모델을 검증한 후 2025~2045년 추계에 이용하였다.
・ 기준 연도 : 2020년(2000~2020년)
・ 검증 연도 : 2021~2023년
・ 추계 연도 : 2025~2045년
본 연구에서 활용한 소지역 단위는 자치구이다. 인구통계학에서 소지역은 특정한 크기로 정의할 수 있는 것은 아니며, 일반적으로 사용 가능한 인구통계 데이터가 제한되어 있는 지역 크기 혹은 특정 인구 임계 값으로 지정할 수 있다(Wilson et al., 2022). 그렇기 때문에 여기에서는 사용 가능한 인구 통계 데이터가 제한되어 있는 지역 크기의 개념을 이용하여 공식적인 장래인구・가구 추계의 통계가 작성되지 않는 단위인 시군구를 소지역 단위로 정의하였다. 특히, 시군구는 우리나라 기초자치단체의 공간적 수준에 해당하기 때문에 소지역 계획에 있어 매우 의미 있는 공간 단위라 할 수 있다.
본 연구에서 활용한 데이터는 서울시 자치구별 인구통계 데이터로, 통계지리정보서비스(sgis.kostat.go.kr)와 통계청(kosis.kr)에서 공개하고 있는 자료를 활용하였다. 해당 자료의 지리적 경계는 2023년 7월을 기준으로 작성된 자료이나, 실제로 서울의 자치구별 경계는 2000년 이후 변경된 적이 없어 단일 경계의 데이터를 활용하는 것이 가능하였다. 전체 데이터의 기간은 2000~2023년으로, 2000~2010년은 5년 단위로 2000년, 2005, 2010년 총 3개년도, 2015~ 2023년은 1년 단위 데이터로 총 9개년도 데이터로 구성되어 있다. 해당 데이터로 인구 및 가구수 자료를 이용하였으며, 주거용 건축물 연면적의 경우 세움터(www.eais.go.kr)에서 공개하고 있는 건축물대장 자료를 이용하였으며, 건축물대장의 주용도가 주택인 건물의 연면적 합을 산출하여 활용하였다. 해당 자료는 2015년 이후 월별로 누적된 자료로, 2000~2010년 사이의 데이터는 작성이 어려워 추세 외삽을 통해 추정하였다.
전체 데이터 구조는 자치구별・가구원수별・가구주 연령별로 구분하여 총 500개의 행으로 구성하였으며, 각각의 행별 결과를 산출하였다.
표 1은 모델별 입력된 데이터와 결과의 프레임을 제시한 것이다.
표 1.
입력 변수 및 입력 데이터의 구조
4. LSTM 모델의 예측력 검증 및 추계 결과
1) LSTM 모델의 예측력 검증
앞서 설계한 LSTM 모델의 예측력을 검증하기 위하여 LSTM 모델의 결과와 다른 가구추계 방법을 이용하여 산출한 결과와 예측 오차를 비교하였다.
예측 오차를 비교하기 위하여 타 가구추계의 비교군을 먼저 작성할 필요가 있다. 여기에서는 가구추계에 빈번하게 사용되는 방법인 가구주율법과 가구전이법을 간소화하여 소지역 단위로 적용・비교하고자 한다.
가구주율법의 경우 통계청 공식통계에서 활용하고 있는 방법으로, 시도별 장래가구추계 결과 중 서울시의 2021~ 2023년 자료를 이용하였다. 통계청 시도별 추계 결과의 경우 전국의 추계 결과를 작성한 후 가구수의 합을 비례배분하도록 보정하는 Top-Down 방식을 취하고 있어 해당 방식을 동일하게 이용하였다. 서울시의 추계 결과를 기준연도(2020년)에 맞춰 자치구별 가구수 비율에 따라 비례배분하여 소지역 단위의 자치구별 추계 결과를 작성하였다.
가구전이법의 경우 인구총조사 패널데이터를 활용하여 전이 매트릭스를 구축하였다. 해당 패널데이터의 경우 서울시 전체의 표본이 약 65,000개(2020년 기준)로, 가구의 특성별로 구분하여 자치구별로 전이 확률을 모두 계산할 수 없어 불가피하게 서울시의 전이 확률을 계산하여 자치구 단위에 일괄적으로 적용하였다. 2021~2023년의 매해 값을 추계하는 것이기 때문에 2019~2020년 단년의 전이 확률을 계산하였으며, 이를 2021~2023년 3년치 추계에 동일하게 적용하였다
가구주율법, 가구전이법 모두 LSTM 모델의 가구추계 결과와 비교하기 위하여 가구의 특성인 가구주 연령(20대 이하/30대/40대/50대/60대 이상) 및 가구원수(1인/2인/3인/4인 이상)에 따른 결과값을 분석하였다.
소지역 단위의 가구추계에 대한 예측력을 평가하기 위한 예측 오차는 평균 절대 비율 오차(MAPE)를 이용하였으며, 해당 예측 오차는 자치구별・가구원수별・가구주 연령별로 구분된 총 500개의 구성에 대해 측정하였다. 표 2는 각 구성별 평균 오차의 평균을 보여주고 있다.
표 2.
소지역 단위 가구추계 결과의 MAPE
| 구분 | 2021 | 2022 | 2023 |
| 가구주율법 | 6.6% | 8.3% | 10.2% |
| 가구전이법 | 15.1% | 20.0% | 23.7% |
| LSTM 모델 | 3.3% | 3.8% | 4.5% |
먼저 가구주율법을 이용해 자치구별로 배분한 경우 2021~2022년 10% 이하의 오차를 보였으나, 2023년은 10%가 넘는 것으로 나타나 기준연도에서 시간이 경과할수록 예측 오차가 커지고 있으며, LSTM 모델에 비해 높은 예측 오차를 보이고 있다.
반면 가구전이법을 통한 추계 결과의 경우 2021년부터 예측 오차가 10% 이상으로 나타났으며, 2023년은 예측 오차가 무려 23.7%로 나타나 단년의 전이 확률을 적용하여 소지역 단위의 가구 특성별 가구를 추계하는 것은 큰 오차로 인해 활용이 어려울 것으로 보인다.
한편 LSTM 모델의 경우 예측 오차가 10% 이하인 경우에만 모델을 구성하도록 설계되어 있어 그 오차는 10% 이내로 나타났으며, 실제 예측 오차는 그보다 훨씬 낮은 3~4% 수준을 유지하고 있다. 자치구별로 오차율은 가구주율법의 경우 0.02%~5.5%를 보이고 있으며, 가구전이법은 0.2%~ 27.1%, LSTM 모델은 0.1%~4.6% 분포로 나타났다. 기존의 일반적인 가구추계 방법들에 비해 본 연구에서 제시하고 있는 LSTM 모델은 총 오차율이 가장 낮으며, 지역별로도 비교적 적은 폭의 오차율을 보이고 있어 소지역 장래가구추계에 활용될 수 있는 우수한 예측 방법임을 시사하고 있다.
2) LSTM 모델을 이용한 장래가구추계 결과(2025~2045년)
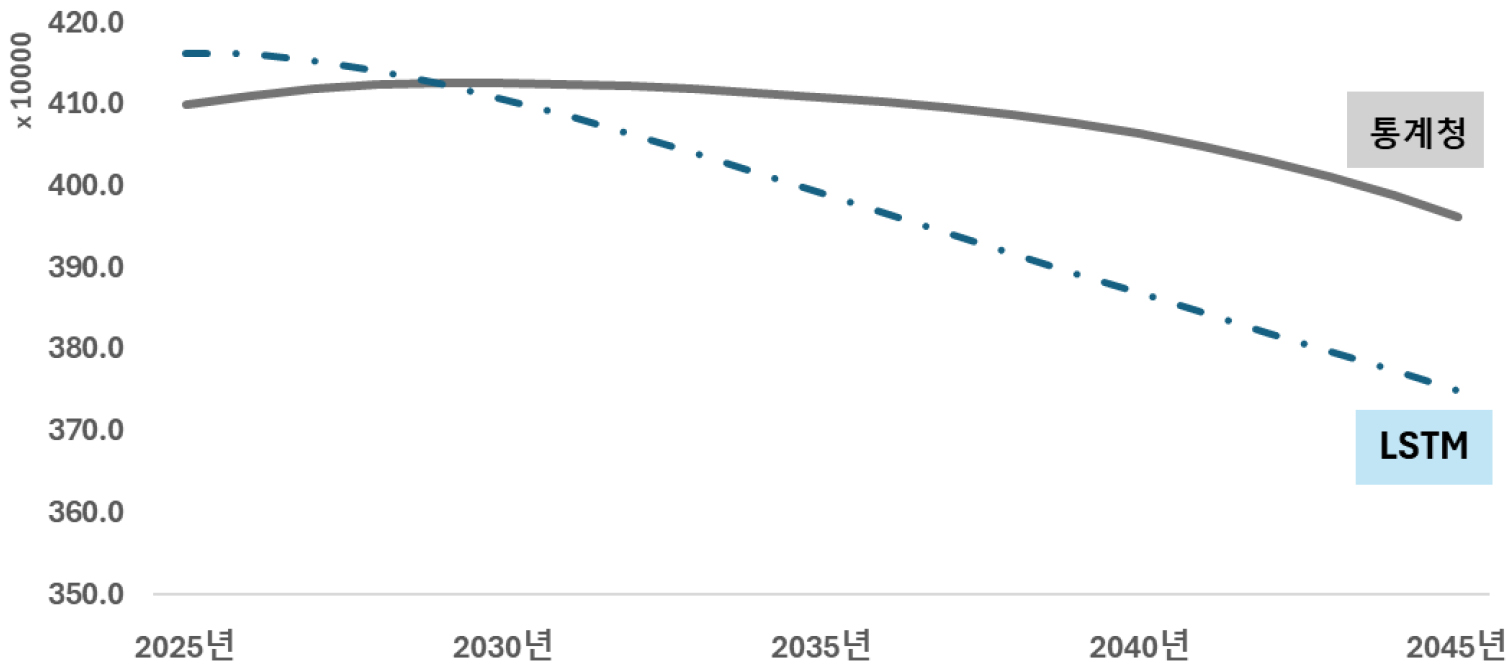
그림 2는 LSTM 모델을 이용하여 가구 특성별・자치구별 가구추계 결과에 대한 연도별 합산을 보여주고 있다. 통계청의 장래가구추계 결과와 비교하여 볼 때, 가구수가 일정 수준 증가까지 감소하는 추세로 반전되는 결과가 나타나 전체적인 추세가 유사하게 나타나는 것을 확인할 수 있다. 통계청의 장래가구추계는 2029년 서울시 412.6만 가구를 정점으로 하여 2045년까지 391.6만 가구까지 감소하는 것으로 나타났으나, LSTM 모델의 경우 2026년 416.1만 가구로 정점을 찍은 후 더 빠른 속도로 가구가 감소하여 2045년 375.0만 수준으로 떨어질 것으로 예측하였다. 통계청의 결과에 비해 보다 짧은 시기에 정점이 나타나며 가구수의 감소폭이 훨씬 더 큰 것으로 예측되었다.
보다 구체적인 가구 특성별로 통계청의 장래가구추계 결과와 LSTM 모델의 결과를 비교하면, 표 3, 표 4와 같다. 먼저 표 3의 가구원수별 가구수를 살펴보면 두 결과 모두 2025~2045년 간 1~4인 가구의 비중은 소폭 달라지나, 거의 유사한 추세를 유지하는 것으로 나타났다. 여전히 1인 가구 비중이 가장 높게 나타날 것으로 예측되며, 다른 가구원수 유형에 비해 1인 가구 비중이 소폭 증가할 것으로 보여진다. 또한 4인 이상 가구 비중은 지속적으로 감소할 것으로 전망되어 두 결과 모두 가구의 분화가 향후 지속적으로 나타날 것으로 예측하고 있다.
표 3.
가구 특성별 가구추계 결과 비교(가구원수별)
표 4.
가구 특성별 가구추계 결과 비교(가구주 연령별)
한편 표 4의 가구주 연령별 가구수 추계를 살펴보면, 통계청 장래가구추계에서 가장 큰 특징은 20대 이하 가구주 비중이 2025년 11.0%에서 2045년 6.2%까지 감소하고, 60대 이상 가구주 비중이 2025년 33.6%에서 2045년 46.9%로 대폭 증가한다는 점이다. LSTM 모델 추계 결과 역시 통계청의 가구추계와 유사한 방향성을 보이고 있다. 즉 20대 이하 가구주 비중은 감소하고, 60대 이상 가구주 비중이 증가할 것으로 예측된다. 하지만 그 변화폭은 두 모델에서 차이가 나는데 LSTM 모델이 비교적 적은 수준의 변화를 예측하고 있다. LSTM 모델에서는 20대 이하의 가구주 비중은 2025년 12.6%에서 2045년 7.8%로 4.8%p 감소하고, 60대 이상 가구주 비중은 2025년 34.1%에서 2045년 41.2%로 7.1%p 정도 증가할 것으로 예측하였다.
소지역 단위의 자치구별 가구수 추계의 공간적 변화를 살펴보면 그림 3과 같다. 좌측의 지도는 통계청의 시도별 장래가구추계를 2025~2045년까지 자치구별로 비례할당한 결과이며, 우측의 지도는 LSTM 결과를 보여주고 있다.
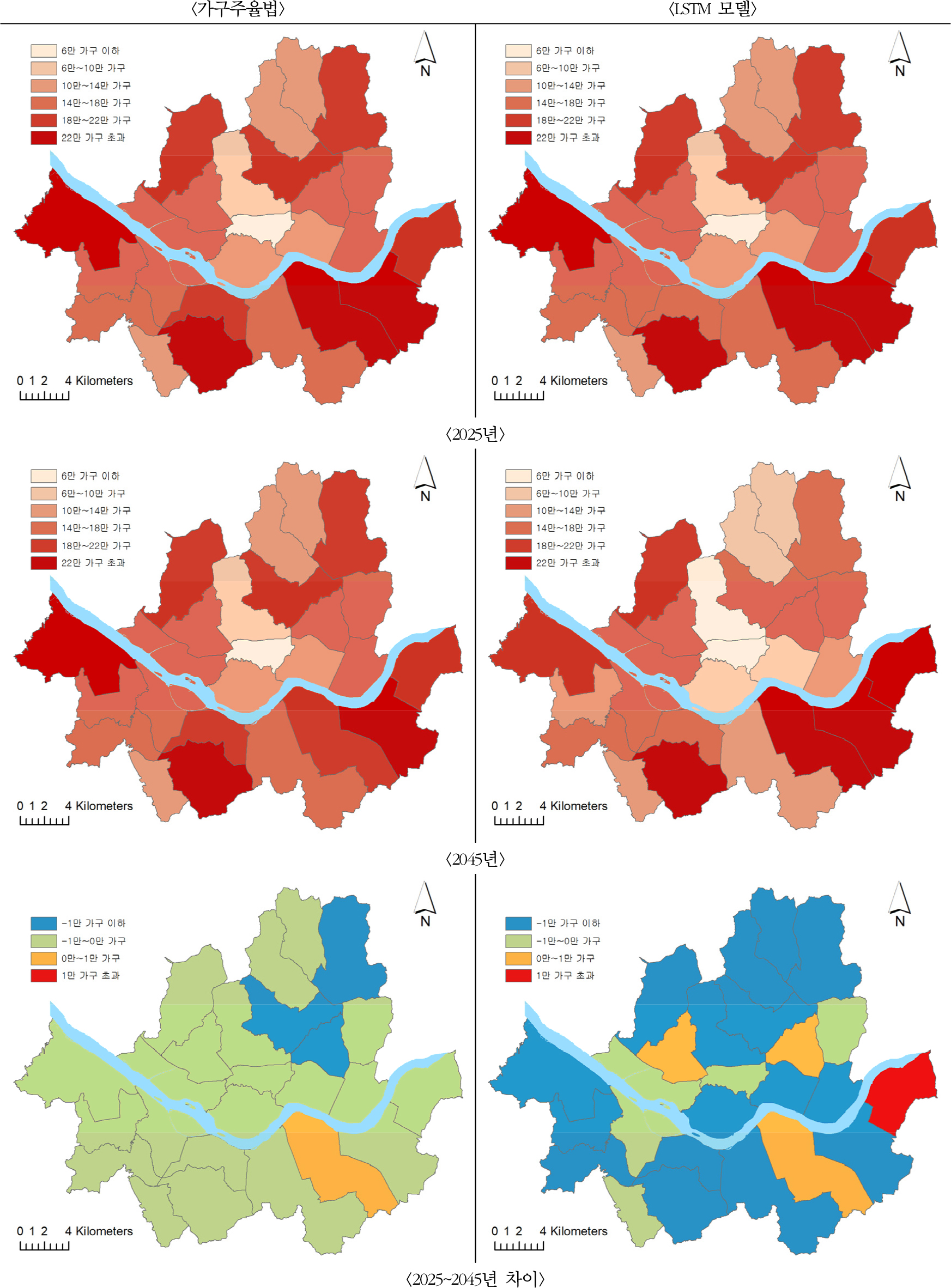
먼저 통계청 장래가구추계를 자치구별로 비례할당한 결과는 기준연도에서부터 그 분포가 거의 변화하지 않기 때문에 2025~2045년까지 분포가 유사한 특성을 보이고 있다. 전반적인 가구수 감소에도 불구하고 1인 가구 비중이 높은 관악구가 가장 많은 가구수를 유지할 것으로 예상되며, 송파구, 강서구, 강남구 등 인구 밀도가 높은 지역을 중심으로 가구수 감소폭이 적을 것으로 예측된다.
하지만 LSTM 모델의 경우 자치구별 주거용 연면적 변화를 추계에 동시에 활용하고 있어 도시의 주거 면적에 대한 공간적 분포가 반영되어 지역적으로 차이가 나는 결과를 보여주고 있다. 통계청 장래가구추계 결과와 유사하게 전반적인 가구수 감소 추세를 보이고 있음에도 불구하고 일부 자치구(강동구・서대문구・동대문구・강남구)에서는 2025~ 2045년 사이 가구수가 증가할 것으로 전망하고 있다. 이러한 자치구들은 20대 이하 가구보다 60대 이상 가구 비중이 높고, 특히 60대 이상 가구 비중의 증가폭이 높을 것으로 전망된다. 또한 2025~2045년 사이 1인 가구는 전반적으로 그 수가 감소할 것으로 예상되는데, 강동구・강남구・동작구・서대문구 등 일부에서는 소폭 증가세가 보일 것으로 예측되었다. 이 지역들은 1인 가구 중 특히 60대 이상 독거 노년 가구들의 증가세가 뚜렷할 것으로 예상된다. 이처럼 가구수가 증가할 것으로 예상되는 지역의 공통적인 점은 최근 건축물 주거용 연면적의 증가가 뚜렷한 지역이라는 점이다. 해당 지역은 최근의 주택 공급 비중이 높았고, 이로 인해 비교적 급격한 가구수 증가를 겪었던 지역으로, 전지역에서 주로 60대 이상과 1인 가구 위주로 가구수 증가가 일어나고 있어 이러한 경향이 미래 추세에도 반영된 것으로 보인다. 이처럼 지역의 주거 환경 변화로 인해 가구수도 지역별로 크게 차이가 날 것으로 예측된다.
2025~2045년 사이 LSTM 모델의 추계 결과에서 특징적인 것은 1인 가구의 지속적인 증가와 20대 이하 가구주 감소 및 60대 이상 가구주의 큰 증가이다. 지면의 제한으로 인해 자치구별로 모든 가구 특성에 대한 추계 결과를 제시할 수 없으나 일부 특징적인 결과를 살펴보면 다음과 같다.
그림 4에서 보는 것과 같이 2025~2045년 사이 1인 가구는 전반적으로 그 수가 감소할 것으로 예상되나, 일부 자치구에서는 소폭 증가세가 보일 것으로 예측되며, 특히 60대 이상 독거 노년 가구 증가폭이 클 것으로 나타나 해당 지역에서는 독거 노인 가구에 대한 대책 마련 등이 필요할 것이다. 또한 20대 이하 가구주의 경우 서울시 전반에서 감소세가 뚜렷하게 나타났으나, 60대 이상 가구주는 전체적인 수의 증가에도 불구하고 자치구별로는 큰 차이를 보이는 것으로 나타났다. 특히 강남・송파・강동 등에서는 뚜렷한 증가가 나타날 것으로 예측되나, 서초・성동・강북・도봉구 등에서는 큰 변화가 없이 그 수가 유지될 것으로 예상되었다.
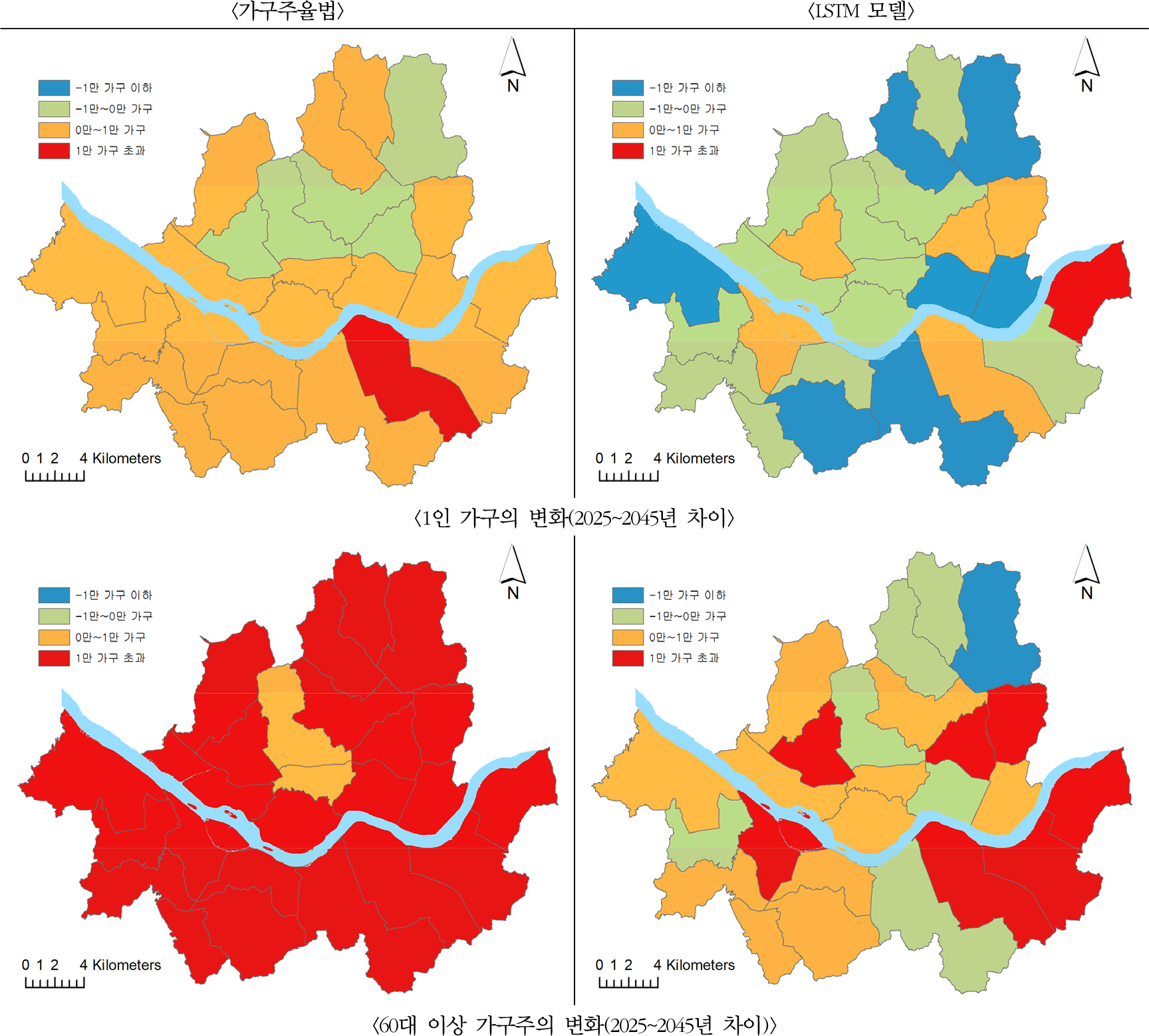
또한 1인 가구 중 60대 이상 가구주의 경우 가장 큰 증가세를 보이고 있는 그룹으로, 전반적으로 증가하는 추세를 보일 것으로 예상되나, 일부 도심권・동북권을 중심으로는 증가 추세가 약할 것으로 예측된다. 한편 지속적으로 감소하고 있는 30~40대 가구주의 3・4인 가구는 서울 전역에서 감소하고 있으며, 장래에도 지속적으로 감소할 것으로 예측된다. 그러나 강동구의 경우 주거용 건축물의 증가가 크게 나타날 것으로 보여 해당 가구가 소폭 증가할 것으로 나타났다.
4. 결론
본 연구는 소지역 단위의 장래가구추계에 활용하기 위한 새로운 방법을 제시하고, 예측력을 검토하여 2025~2045년의 가구추계 예측 결과를 제시하고 있다. 소지역 단위에 활용할 수 있는 새로운 방법인 LSTM 모델은 딥러닝 방법의 일종으로 시계열 데이터를 처리하는데 우수한 성능을 가진 것으로 알려져 있으며, 본 연구에서는 이를 이용하여 서울시 자치구별 장래가구추계 모델링을 수행하였다.
LSTM 모델을 활용하여 소지역 단위로 가구 특성을 담은 가구수를 추계하였으며, 실제 검증 결과 해당 모델의 예측 오차는 3% 내외로 나타나 소지역 단위 가구추계에 높은 예측력을 보여 장래가구추계의 실제적인 적용 가능성을 확인할 수 있었다. 또한 기존의 가구추계 방법들과 비교 분석한 결과, 가구주율법을 소지역 단위로 적용하여 비례할당할 경우 시간이 경과할수록 전체 오차가 누적되는 패턴을 보이며, 시간에 따른 지역별 분포의 차이를 제대로 반영하지 못하였다. 반면 본 연구에서 제시한 LSTM 모델은 오차 누적 문제가 거의 발생하지 않고, 지역적 변이가 보다 잘 드러나는 결과를 보여주었다.
본 연구에서 제시한 딥러닝 기반의 다변량 LSTM 모델은 가구의 특성별로 가구수 변화를 소지역 단위로 추계하는 데 높은 예측력을 보이는 것으로 검증되었으며, 모델링 결과는 통계청의 장래가구추계 결과와 비교할 때 유사한 추세를 보이는 것으로 나타났다. 특히, LSTM 모델에서는 소지역에서 고려해야 할 거주 환경의 공간적 변화도 동시에 고려할 수 있어 소지역 단위에서의 변이가 다양하게 포착되는 것을 확인할 수 있었다.
장래가구추계는 다양한 사회 분야에서 활용성이 점차 확대되고 있으며 실제 적용 가치가 매우 높은 통계 자료이다. 정부 및 지자체의 다양한 지역 계획 및 정책 수립에 직접적으로 활용될 수 있을 뿐만 아니라 미래의 재정 전망이나 국토종합계획 등에도 유용하게 할용할 수 있다. 그러나 기존의 공식적인 장래가구추계 자료는 공간 스케일이 큰 시도 단위로만 작성되고 있어 소지역에 대해 미시적으로 활용하기에는 여전히 제한적이며, 그 한계가 뚜렷하다.
본 연구의 결과는 기초자치단체 수준의 가구추계를 보다 신뢰성 있게 보여줌으로써 지역적 특성이 보다 잘 반영된 지역 계획이나 정책 수립에 활용될 수 있을 것으로 기대된다. 또한 보다 작은 공간 단위의 미시적 분석이 요구되는 주택 시장이나 주택 수요 연구에도 크게 도움을 줄 것으로 기대된다.
한편 본 연구의 모델 훈련에 활용한 데이터는 총 9개 연도의 데이터로, 이보다 장기간의 과거 시계열을 활용할 경우 보다 더 정확한 추계 결과의 산출이 가능할 것이나 현재 인구총조사의 연계성 문제로 인해 더 과거의 데이터를 활용할 수 없는 점이 아쉬운 점으로 남는다. 또한 본 연구의 추계 프레임워크가 타 지역에서도 동일하게 높은 예측력을 보이는 지는 여전히 미래 연구 과제로 남아 있다.
