

1. 연구의 필요성 및 목적
2. 분석자료 및 방법
1) 분석자료
2) 분석방법
3. 네이버후드 효과 연구를 위한 작동스케일 탐색
1) 측정스케일에 따른 공간단위 임의성의 문제(MAUP)
2) 거리에 따른 공간적 자기상관의 변화
4. 결론 및 제언
1. 연구의 필요성 및 목적
「대한민국 헌법」 제31조 1항에 의하면 모든 국민은 능력에 따라 균등하게 교육을 받을 권리를 가진다. 즉, 어디에 사는지와 관계없이 모든 국민은 균등하게 교육을 받을 권리가 있는 것이다. 따라서 학생 개인의 학습 능력에 따른 교육결과의 차이는 있을 수 있으나, 그들이 살고 있는 지역이 어디냐에 따라 교육결과가 차이 나는 것은 결코 바람직한 현상이라 볼 수 없다. 그럼에도 불구하고 우리나라에서 교육의 공간적 격차는 늘 논란의 중심이며, 발생 원인에 대해서도 개인의 영향인지 혹은 특정지역(예: 학구)으로의 진입에 따른 영향인지에 대한 논쟁이 계속되어 왔다. 이때 전자는 구성효과(compositional effects), 후자는 맥락효과(contextual effects)로 연결될 수 있다. 소위 말하는 강남8학군1)에 이를 대입해보면 구성효과의 입장은 ‘강남 8학군에 살고 있는 학생들의 학업성취도가 상대적으로 높은 것은 원래 그 학생들의 입학성적이 높기 때문’으로 개인의 영향을 강조하는 입장이다(예: 박부권・이지혜, 1989; 성기선, 2003). 반면, 맥락효과는‘강남 8학군과 같은 좋은 학교군에만 진입한다면 대학 진학에 보다 유리할 것’이라는 입장으로, 특정 지역의 영향을 강조하는 것이다(예: 김천기, 2005). 여기서 말하는 맥락효과가 본 연구의 주요 개념인 ‘네이버후드 효과(neighborhood effects)2)’를 의미한다. 네이버후드 효과란, 윌슨(Wilson, 1987)의 저서 출판 이후로 다양한 분야에서 활발히 활용되는 개념으로,“특정한 네이버후드에 속한 개인들이 유사한 행위 혹은 선택을 하도록 이끄는 구조적인 요인”을 뜻한다(Lee, 2009; 2020). 이는 학생들의 교육성과나 청소년들의 비행과 같은 교육현상의 지리적인 맥락을 설명하는 주요한 개념적 틀로 활용되고 있다(예: Lupton, 2006; Sykes and Kuyper, 2009). 그런데 이러한 네이버후드 효과 연구와 관련하여 몇 가지 방법론적 이슈가 존재한다. 예를 들어 네이버후드 효과 연구에 앞서 네이버후드의 공간적 범위는 어떻게 설정할 것인지 혹은 네이버후드 효과 연구에 적절한 분석방법을 사용했는지, 분석에 사용된 변수는 적절한지 등이다. 본 연구는 그 중에서도 네이버후드의 공간적 범위 설정에 주목하고자 한다. 이는 네이버후드 효과가 기본적으로 특정 공간을 전제로 한다는 측면에서 매우 주요한 문제이다. 그럼에도 불구하고 그동안 네이버후드의 공간적 범위가 어디까지인가에 대한 충분한 고민 없이 연구를 진행한 경우가 많았다. 국・내외를 막론하고 다양한 수준의 공간단위가 네이버후드 효과에 대한 실증연구에서 사용되고 있었다. 먼저 해외 연구의 경우, 우편번호구역(postal zip code)부터 센서스 트렉트(census tract), 초등학교 통학구(elementary school attendance areas), 고등학교 통학구(high school attendance areas)까지 광범위하게 규정되고 있었다(Jenks and Mayer, 1990). 주로 센서스 트렉트 혹은 블락그룹과 같은 비교적 작은 공간단위를 사용하는 경우가 많았지만(Dietz, 2002 참조), 카운티(county)와 같이 넓은 공간스케일에서의 연구를 진행한 경우도 있었다(Del Bono, 2004; Lupton and Kneale, 2012에서 재인용). 국내의 경우에도 네이버후드 효과 연구는 많지 않지만 역시 다양한 공간단위를 사용하고 있었다. 곽현근(2007)은 네이버후드를‘걸어서 5 ~ 10분 정도의 거주지 주변의 장소’로 규정한 반면, 김형용(2013)은 행정동 수준으로, 이지현(2019)3)은 시군구 단위를 네이버후드 수준으로 상정했다.
그렇다면 이처럼 다양한 공간단위 중 어떠한 공간단위가 네이버후드 효과 연구에 가장 적합한지에 대한 의문을 제기할 수 있다. 그리고 대개 시간이 흘러 특정 분야의 연구가 증가하면 어느 정도 일관된 결과를 도출할 수 있는데, 네이버후드 효과 연구의 경우 여전히 합의된 결과를 도출하기 어려운 측면이 있다. 그 이유 중 하나가 각각의 연구들이 각기 다른 공간단위를 사용하기 때문이기도 하다(Lupton and Kneale, 2012). 이와 관련하여 Dietz(2002)는 네이버후드의 경계가 이론적인 고려 없이 “구득이 가능한 데이터셋의 한계에 의해 규정”되었다며 비판하기도 하였다(Dietz, 2002: 541). 즉, 연구 주제에 따라 일종의 작동스케일4)이라고도 말할 수 있는 메커니즘이 달라짐에도 불구하고, 많은 연구에서 단순 구득이 가능한 데이터를 사용해온 것이다. 이는 개념적인 문제를 떠나 방법론적으로도 매우 중요한 문제가 될 수 있다. 왜냐하면 네이버후드로 어떤 공간단위를 사용하느냐에 따라 연구 결과가 달라질 수 있기 때문이다. 예를 들어 어떤 특정 현상에 대하여 네이버후드 효과가 존재하지 않는다는 결과가 도출되었을 때, 그것은 실제로 네이버후드 효과가 없다는 의미일 수도 있지만, 적절한 공간단위를 사용하지 않았음을 의미할 수도 있는 것이다(Lupton and Kneale, 2012 참고). 이러한 문제는‘공간단위 임의성의 문제(Modifiable Areal Unit Problem: 이하 MAUP)5)’와도 관련이 있다.
본 연구에서는 그러한 문제의식에서 네이버후드 효과 연구의 선결적 과제로서, 작동스케일 개념을 활용하여 네이버후드의 공간단위를 규정할 수 있는 실증적인 방법을 제안하고자 한다. 그리고 이를 통해 교육성과에 대한 네이버후드 효과 연구에 적용 가능한 네이버후드 공간단위를 탐색하고자 한다. 본 연구의 결과는 추후 네이버후드 효과 연구 시 결과의 왜곡 및 MAUP의 영향을 최소화할 수 있는 하나의 대안이 될 수 있을 것이다.
2. 분석자료 및 방법
1) 분석자료
작동스케일 탐색을 위해서는 여러 가지 사항들에 대해 고려해야 하지만, 연구 목적에 맞는 데이터 선정 역시 중요한 사안 중 하나이다. 이에 본 연구에서는 대학수학능력시험 결과가 우리나라의 교육성과를 나타내는 대표적인 지표로 판단하여 이를 활용하고자 하였다. 해당 시험은 대다수의 학생들이 응시하는 국가수준의 시험일뿐만 아니라, 그동안 정책적 변화는 있어왔지만 여전히 가장 주요하게 여겨지는 대학 입학 전형이기 때문이다. 분석을 위한 데이터는 교육부와 학술교육학술정보원(KERIS)에서 운영하는 에듀데이터 서비스 시스템(EduData Service System, 이하: EDSS)을 통해 제공 받았다. 모집단의 70%로 층화추출된 227건의 학교수준 데이터를 제공 받았으며, 그 중 학교유형에 따라 일반계에 해당하는 일반고등학교, 자율형 고등학교(자율형 사립고/자율형 공립고), 특수목적고등학교(외국어고・국제고/과학고) 167건에 대해서만 분석을 수행하였다.6)
활용 가능한 대학수학능력시험 결과는 표준점수, 등급, 백분위 세 가지 종류로 구분할 수 있는데, 본 연구에서는 표준점수와 등급 자료를 활용하였다. 표준점수는 표준편차와 평균을 활용하여 산출되며7), 학생이 취득한 원점수가 평균으로부터 얼마나 떨어져있는지를 의미한다(한국교육과정평가원, 2018). 이는 공간 분석 시 평균을 중심으로 점수가 유사한 학교끼리 얼마나 공간적으로 군집되어있는지 살펴보는데 유용하게 활용될 수 있다. 두 번째 활용자료는 등급 자료인데, 등급은 수험생의 표준점수를 바탕으로 등급별 비중에 따라 9등급으로 분류된다. 등급은 매년 일정한 비율로 정해지므로 표준점수에 비해 해석이 상대적으로 용이하여 많은 연구에서 활용되고 있다(예: 조지민 등, 2011; 정재훈・김경민, 2014). 등급별 성적 비율에 따라 전체 수험생의 상위 4%는 1등급, 그 다음 7%는 2등급으로 1-2등급은 상위 11%의 학생들에 해당된다(한국교육과정평가원, 2018). 정재훈・김경민(2014)은 대략 상위 10%의 학생들이 소위 말하는 명문대로 진학하기에, 1-2등급 학생의 비중을 명문대 진학률을 대변하는 것으로도 볼 수 있다고 밝혔다. 그러한 점들을 감안하여 본 연구에서도 표준점수와 함께 1-2등급 학생의 비중 역시 분석을 위한 자료로 활용하였다. 다만, 일반적인 행-비중 계산방식은 학교별로 상이한 규모수준(학생 수)을 반영하지 못하는데, 그러한 한계를 보완하기 위해서 이상일(2008)이 제안한 표준화방식(표준화 상이점수, Standardized Score of Dissimilarity 이하: SSD)을 활용하였다. SSD의 산출식은 식 (1)과 같다.
수식 (1)의 는 해당 변수에 대한 특정 학교의 비중을, 는 준거변수에 대한 특정학교의 비중을 의미한다(이화정 등, 2013 참고). 위 수식을 본 연구에 적용하면, 는 특정 과목의 1-2등급을 받은 모든 학교의 학생 수 대비 각 학교별 1-2등급을 받은 학생 수를 나타낸다. 는 샘플 학교 전체 3학년 학생 수 대비 각 학교의 3학년 학생 수로 설정한다. 즉, 정리하자면 SSD는 1-2등급 학생 수의 비율을 나타내되, 학교별로 상이한 규모수준(3학년 학생 수)을 고려한 계산 값이다
(1) 분석의 시간적・공간적 범위
분석의 시간적 범위는 2016년 겨울에 시행한 2017학년도 대학수학능력시험의 결과(국어, 영어, 수학 가, 수학 나)이며8), 공간적 범위는 서울시이다. 서울은 교육의 수요와 공급의 공간적 집중이 동시에 나타나는 곳이면서, 교육이주 등 교육열과 관련한 현상(예: 학교분리 혹은 거주지 분리 등)이 나타나는 대표적인 공간이기 때문이다(예: 최은영, 2004; 정수열・이정현, 2016).
(2) 공간단위: 측정스케일
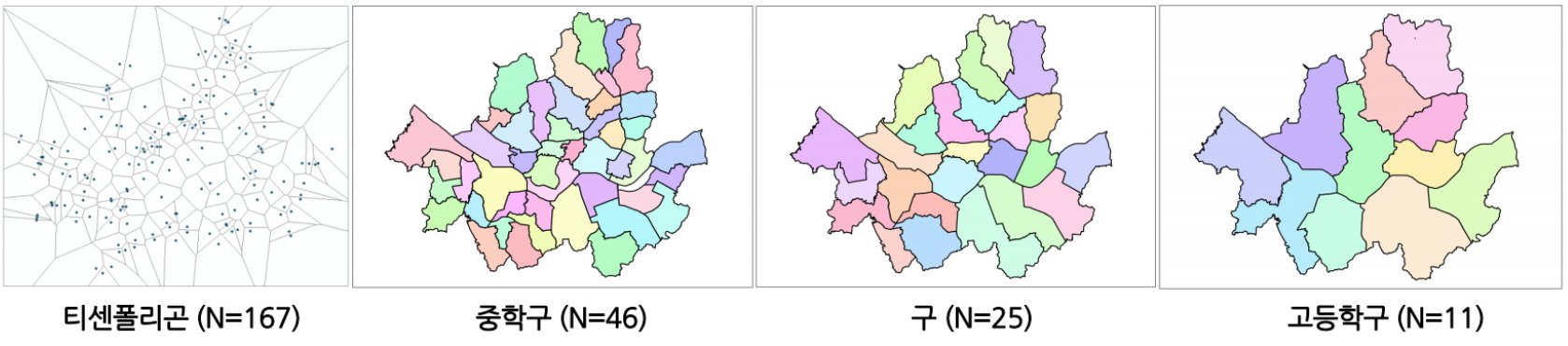
본 연구에서 활용하고자 하는 측정스케일은 티센폴리곤(Thiessen polygon)9), 중학구, 시군구, 고등학구 총 4종류의 공간 스케일이다.10) 가장 최소단위의 측정스케일은 티센폴리곤으로, 학교데이터를 지오코딩한 후 ArcMap을 활용하여 생성하였다. 이때 전역적 공간적 자기상관의 값은 티센폴리곤, 중학구, 시군구, 고등학구 4개의 측정스케일에서 모두 산출되었고, 베리오그램과 코렐로그램 분석은 티센폴리곤 단위에서만 수행되었다. 중학구와 고등학구의 경계데이터11)는 학구도 안내서비스를 통해 제공 받았으며, 구 데이터는 통계청 SGIS에서 제공받았다. 본 연구에 사용된 4가지 종류의 측정스케일은 그림 1과 같다.
2) 분석방법
앞서 밝혔듯이 작동스케일 탐색은 매우 중요함에도 불구하고, 관련 연구 및 방법론적 논의는 부족한 실정이다. 작동스케일 탐색을 위해서는 베리오그램(variogram), 코렐로그램(correlogram), 프랙탈분석(fractal analysis) 등의 방법이 주로 사용되어 왔으며(Lam and Quattrochi, 1992), 국내에서는 신정엽(2005)의 연구가 대표적이다. 이러한 점을 고려하여 본 연구에서도 탐색적 공간데이터 분석(Exploratory spatial data analysis: 이하 ESDA)의 관점에서 실증적 연구를 통해 작동스케일을 도출하고자 한다. 작동스케일 탐색에 앞서 먼저 네이버후드의 개념적 특성에 대한 규정이 필요하다. 네이버후드 개념에 대해서는 다양한 논의가 있지만, 로버트 파크(Robert Park)와 어니스트 버제스(Ernest Burgess)의 자연지역(natural areas) 개념은 오늘날 네이버후드 개념의 근간이 된다고 볼 수 있다(Sampson et al., 2002).12) 자연지역은 일종의 생태학적 단위로, 내부적으로 다른 지역과 구분되는 동질성을 지니는데(신정엽, 2007 참고), 본 연구에서도 작동스케일을 내부적으로는 동질적이고 외부적으로는 이질적인 하나의 범위로 가정하였다. 이에 방법론적으로는 공간적 자기상관의 개념을 활용하여, 수치적 유사성이 더 이상 공간적으로 인접해서 나타나지 않는 지점을 네이버후드의 경계로 판단하였다. 이를 위해 먼저 측정스케일별 전역적 공간적 자기상관의 값을 산출하여 스케일에 따라 결과값이 달라진다는 것을 확인하고, 공간적 코렐로그램과 베리오그램 분석을 통해 분석에 적절한 스케일을 탐색하고자 하였다.
(1) 전역적 공간적 자기상관 탐색
공간적 자기상관은 본 연구에서 핵심이 되는 개념 중 하나로, 수치적으로 유사한 속성들이 공간적으로 어느 정도로 인접해 있는지와 관련이 있다(Anselin and Bera, 1998). 이는 크게 양의 공간적 자기상관과 음의 공간적 자기상관으로 구분할 수 있다. 양의 공간적 자기상관이란, 수치적으로 유사한 속성을 지닌 관측지가 공간적으로 군집되어 있는 것을, 음의 공간적 자기상관은 그 반대의 상황을 의미한다. 전역적 공간적 자기상관 탐색을 위한 다양한 통계량이 존재하는데, 본 연구에서는 모런 통계량(Moran, 1948)과 이상일의 통계량(Lee, 2001a; 2001b; 2004; 이상일 등, 2015)을 사용하고자 한다. 이들 통계량의 수식은 아래와 같다.
여기서 은 공간단위 수를 의미하며, ,는 각각 구역의 변수 값, 구역의 변수 값을 나타낸다. 는 변수값들의 평균이며, 는 공간가중치를 의미한다. 우선, 모런 통계량은 공분산(covariance)을 기본원리로 삼으며, 대체로 –1에서 1사이의 값을 가진다. 거의 0이상은 양의 공간적 자기상관을, 거의 0미만은 음의 공간적 자기상관을 나타낸다. 그리고 이상일의 통계량 역시 전역적 공간적 자기상관을 측정하는 통계량으로, 0에서 1사이의 값을 지닌다. 1에 가까울수록 양의 공간적 자기상관을 나타내고, 0에 가까울수록 공간적 자기상관이 나타나지 않거나 음의 공간적 자기상관을 의미한다. 앞서 설명한 두 통계량(기어리 통계량과 모런 통계량)과 통계량의 가장 큰 차이는 공간근접성행렬13)의 주대각 요소에 있다. 기어리 통계량과 모런 통계량은 주대각 요소를 0으로 상정한 반면, 통계량의 경우 관측개체(지점)와 그 인접지역을 함께 포함하므로 주대각 요소가 0이 아니다. 즉, 다시 말하면 지점과 그 인접지역들까지 모두 포함한 하나의 국지적인 집합체(local set)를 분석의 단위로 상정한다는 것을 뜻한다(이상일 등, 2015; 2016). 이에 다른 통계량에 비하여 수치적으로 유사한 값들이 공간적으로 얼마나 군집해있는지 파악하기에 효과적이다. 모런 통계량의 추정은 ArcMap의 Arcpy를 활용하였으며, 기어리 통계량과 이상일의 통계량은 R을 활용하여 추정하였다.
(2) 공간적 코렐로그램 분석
공간적 코렐로그램(spatial correlogram)은 거리에 따른 공간적 자기상관의 변화를 시각적으로 나타낸 그래프로(Cliff and Ord, 1981), 상관그램이라고도 불린다. 거리에 따라 공간적 자기상관이 어떻게 변화하는지 효과적으로 보여줄 수 있어, 지리학 뿐 아니라 다양한 학문분야에서 특정 현상의 시공간 확산과정 및 공간패턴 분석에 유용하게 쓰일 수 있다. 예를 들어 Lam et al.(1996)은 미국의 4개 지역에서의 에이즈의 시공간적 확산 패턴 탐색을 목적으로, Wheeler(2001)는 경제활동이 작동하는 공간적 범위 탐색을 위하여 코렐로그램을 활용하였다. 또한 Queiroz et al. (2010) 역시 브라질 풍토병의 공간적 발생 범위를 확인하기 위해서 공간적 코렐로그램을 활용하는 등 다양한 분야에 적용되고 있다. 본 연구에서도 그러한 맥락에서 교육성과의 작동스케일 탐색을 위해 공간적 코렐로그램을 활용하였다. 통상적으로 코렐로그램의 X축에는 거리 혹은 공간 지체(spatial lags)를 설정, Y축에는 공간적 자기상관의 정도를 표현하는데, 본 연구에서 Y축은 모런 통계량의 값을, X축의 공간 지체는 10으로 설정하였다. 이때 공간근접성행렬은 퀸(queen)14)으로 설정 후 행표준화하였다. 공간적 코렐로그램 분석을 위해서는 R의 spdep 패키지를 활용하였다.
(3) 베리오그램 분석
베리오그램은 거리에 따라 각 지점들 간의 속성값이 얼마나 유사한지(혹은 이질적인지)를 파악할 수 있는 그래프로, 지구통계학에서 거리에 따른 공간적 자기상관의 탐색을 위해 주로 사용된다. 베리오그램15)은 지점과 지점에서 일정거리()만큼 떨어진 속성값의 차이 제곱의 기댓값으로(최종근, 2002 참고), 수식은 다음과 같다(Matheron, 1965; Oliver and Webster, 2014에서 재인용). 여기서 는 각 일정거리만큼 떨어진 모든 쌍(pairs)의 수를 의미한다.
베리오그램은 거리가 증가함에 따라 점차 이질성이 증가하여 두 지점의 속성 값들이 아무런 관계가 없는 특정 거리에 도달하게 되는데 이를 상관거리(range)라고 한다. 상관거리는 공간적 자기상관이 더 이상 발생하지 않는 거리 범위로(Lloyd, 2014), 많은 연구에서 적합한 공간 스케일 탐색을 위하여 활용되고 있다(예: 류희영 등, 2008; 이창로・박기호, 2013). 이때 신뢰성 있는 베리오그램을 산출하기 위해서는 샘플의 수, 각 구간의 간격(lag interval and bin width), 최대범위의 설정 등이 중요하게 여겨진다(Oliver and Webster, 2014). 샘플의 수는 통상적으로 150 ~ 200개 이상이면 신뢰할 수 있는데(Webster and Oliver, 1992), 본 연구의 데이터는 167개로 해당 조건을 충족한다. 각 구간의 간격 설정 역시 중요한데, 본 연구에서는 각 학교들로부터 가장 가까운 학교들의 평균거리인 ‘최근린 평균거리(average nearest neighbor)’를 활용하고자 하였다(Webster and Oliver, 2007; Guo et al., 2019 참고). 최근린 평균거리는 793m16)로, ArcMap을 통해 산출하였다. 마지막으로 분석의 최대범위(coverage 혹은 maximum distance) 또한 신뢰할 수 있는 베리오그램 산출을 위해 고려되어야 할 부분이다. 본 연구에서는 모든 학교들간의 관계를 고려하기 위해서 모든 쌍(pairs)의 이격 거리를 산출하였으며, 그 중 최대 이격 거리(32,857m)를 연구지역의 크기(size)로 상정하였다. Matzke et al.(2014)는 베리오그램의 최대거리는 연구지역 크기의 1/2 ~ 3/4 정도의 범위를 갖는 것이 좋다고 제안하였는데, 본 연구에서도 해당 가이드라인에 따라 19,800m로 최대거리를 설정하였다. 그리고 본 연구의 베리오그램 분석은 등방성(isotropy)가정 하에 진행하였으며, 이론적 베리오그램 적합을 위해서는 여러 가지 모형17) 중 지수모형(exponential model)을 활용하였다. 베리오그램은 R의 gstat 패키지를 활용하여 산출하였다.
3. 네이버후드 효과 연구를 위한 작동스케일 탐색
1) 측정스케일에 따른 공간단위 임의성의 문제(MAUP)
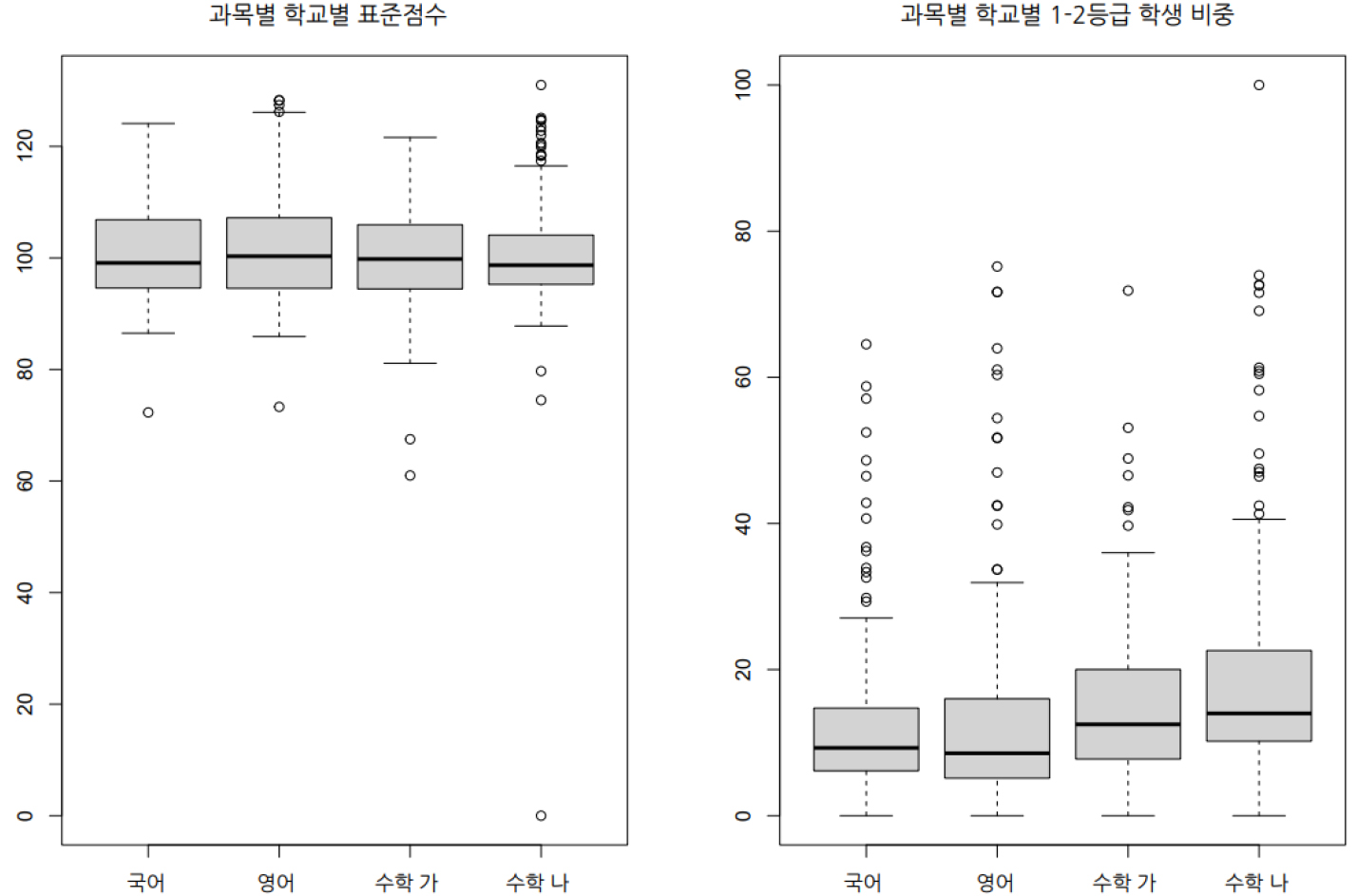
앞서 밝힌 바와 같이 측정스케일에 따라 연구결과가 달라질 수 있기 때문에 측정스케일의 선택은 매우 중요하다. 이에 이번 장에서는 ESDA의 관점에서 측정스케일에 따라 기술통계치가 어떻게 변화하는지, 그리고 공간적 자기상관의 값이 어떻게 변화하는지 살펴보고자 한다. 각 측정스케일별 통계치의 변화를 살펴보기에 앞서 박스플랏을 통해 학교별 표준점수와 1-2등급 학생 비중에 대해서 살펴보았다(그림 2). 2017학년도 대학수학능력시험의 표준점수는 국어, 영어, 수학 영역에서 평균이 100, 표준편차는 20으로 변환되었다(한국교육과정평가원, 2016). 이에 박스플랏 상에서도 100점을 중심으로 성적이 비교적 고르게 분포함을 확인할 수 있다. 수학 나의 경우, 다수의 이상치(아웃라이어)가 존재하는 것을 확인할 수 있었다. 그러나 다른 과목의 경우 사실상 박스플랏을 통해 데이터 구조를 살펴보았을 때 특이한 점을 발견하기는 어려웠다. 그러나 각 학교별 1-2등급의 비중은 표준점수와는 달리 각 학교 간 편차가 크다는 것을 확인할 수 있었다. 다음으로 과목별 학교별 1-2등급 학생 비중에 대한 박스플랏을 살펴보았을 때, 학교 간 비중의 차이가 크고 상당한 수의 이상치가 존재한다는 것을 확인할 수 있었다. 예를 들어 모든 과목에서 1-2등급 학생 수 비중의 중앙값은 20%를 넘지 않는다. 그러나 영어와 수학 가의 경우 거의 80%의 학생이 1-2등급을 받은 학교도 있으며, 심지어 수학 나의 경우 해당 학교에서 수학 나를 응시한 학생의 100%가 1-2등급을 받는 경우도 있다.
다음으로 측정스케일별로 과목별 수능 표준점수의 기술통계치가 어떻게 변화하는지에 대해 살펴보았다(표 1). 먼저 각 과목별 측정스케일별 표준점수의 평균을 살펴보면 어떤 측정스케일이든 영어 점수가 가장 높고, 그 다음은 국어, 수학 나, 수학 가 순으로 높았다. 표준편차의 경우에도, 다른 과목에 비해 영어의 편차가 가장 크다는 것을 확인할 수 있었다. 표준편차는 많은 교육지리학 연구에서 교육격차 탐색을 위한 기초 지표로 활용되고 있다(예: 추경모, 2012; 김준형, 2018). 표준편차가 크다는 것은 학교 간 학업성과의 격차가 크다는 것을 의미하며, 반대로 표준편차가 작으면 학교 간 학업성과의 격차가 작다는 것을 의미한다. 이러한 점에 미루어볼 때 영어점수의 편차가 가장 크다는 것은 다른 과목에 비해 학교 간 영어성적의 격차가 크다는 것으로 해석할 수 있다. 사실 우리나라는 일상적으로 영어에 노출될 수 있는 기회가 적기 때문에 영어능력의 향상은 의식적인 교육투자를 통해서 이루어질 수밖에 없다(김희삼, 2011). 이러한 우리나라의 영어교육특성을 감안할 때, 영어점수의 학교 간 편차는 교육투자의 지역적 편차로부터 기인되었을 것으로 예상해볼 수 있다. 보다 정확한 과목별 변동 폭 비교를 위하여 변동계수(Coefficient of Variation: CV)를 산출하였다. 변동계수는 표준편차를 평균으로 나눈 값으로, 자료 비교에 유용하게 사용될 수 있다. 측정스케일에 따른 변동계수를 살펴보면, 모든 과목에서 측정스케일이 커질수록 변동계수는 작아지는 것을 관찰할 수 있다. 이는 측정스케일이 증가할수록 데이터 합역에 따라 이상치들이 평균값으로 수렴하는 경향이 있기 때문이다. 그에 따라 변수의 변량 역시 감소하는 것이다(이상일, 1999 참조). 이러한 현상은 변동계수뿐만 아니라 각 측정스케일의 최솟값과 최댓값의 변화에서도 확인할 수 있다. 측정스케일이 커짐에 따라 모든 과목에서 표준편차가 감소하는 것 역시 같은 맥락으로 해석할 수 있다. 그러한 양상은 수능 1-2등급 학생의 비중(SSD)을 통해서도 확인할 수 있다. 다만, SSD는 수식(1)에 따라 평균은 0, 표준편차는 1로 산출되므로 평균과 표준편차는 표에서 제외하였다. 표 2를 통해 측정스케일별로 최댓값과 최솟값이 상이함을 확인할 수 있다. 이 역시 가장 작은 측정 스케일인 티센폴리곤 수준에서 최댓값과 최솟값의 편차가 가장 크게 나타났으며, 이들의 편차는 합역 수준이 높아질수록 감소하는 경향을 보였다.
표 1.
과목별 측정스케일별 기술통계(표준점수)
표 2.
과목별 측정스케일별 기술통계(1-2등급 SSD)
그러나 측정스케일에 따른 기술통계치의 변화를 표 1, 2와 같이 정리하였을 때, 파악할 수 있는 정보는 비교적 제한적이다. 예를 들어 중학구 수준에서 국어의 평균점수가 100.29일 때 어느 중학구에서 평균에 가까운 점수를 가지는지, 혹은 어느 중학구에서 최댓값 혹은 최솟값을 가지는지 제시한 표만으로는 확인이 어렵다. 뿐만 아니라 점수가 높은 학교(혹은 지역)들이 집중되어 있는지 혹은 분산되어 있는지, 만약 공간적으로 집중되어 있다면 어느 지역에 집중되어 있는지 등에 대한 정보 역시 파악하기 어렵다. 그러나 측정스케일에 따른 수능 표준점수와 1-2등급 학생 비중을 지도화하는 것만으로도 교육결과의 공간적 격차의 파악이 가능할 것이다.
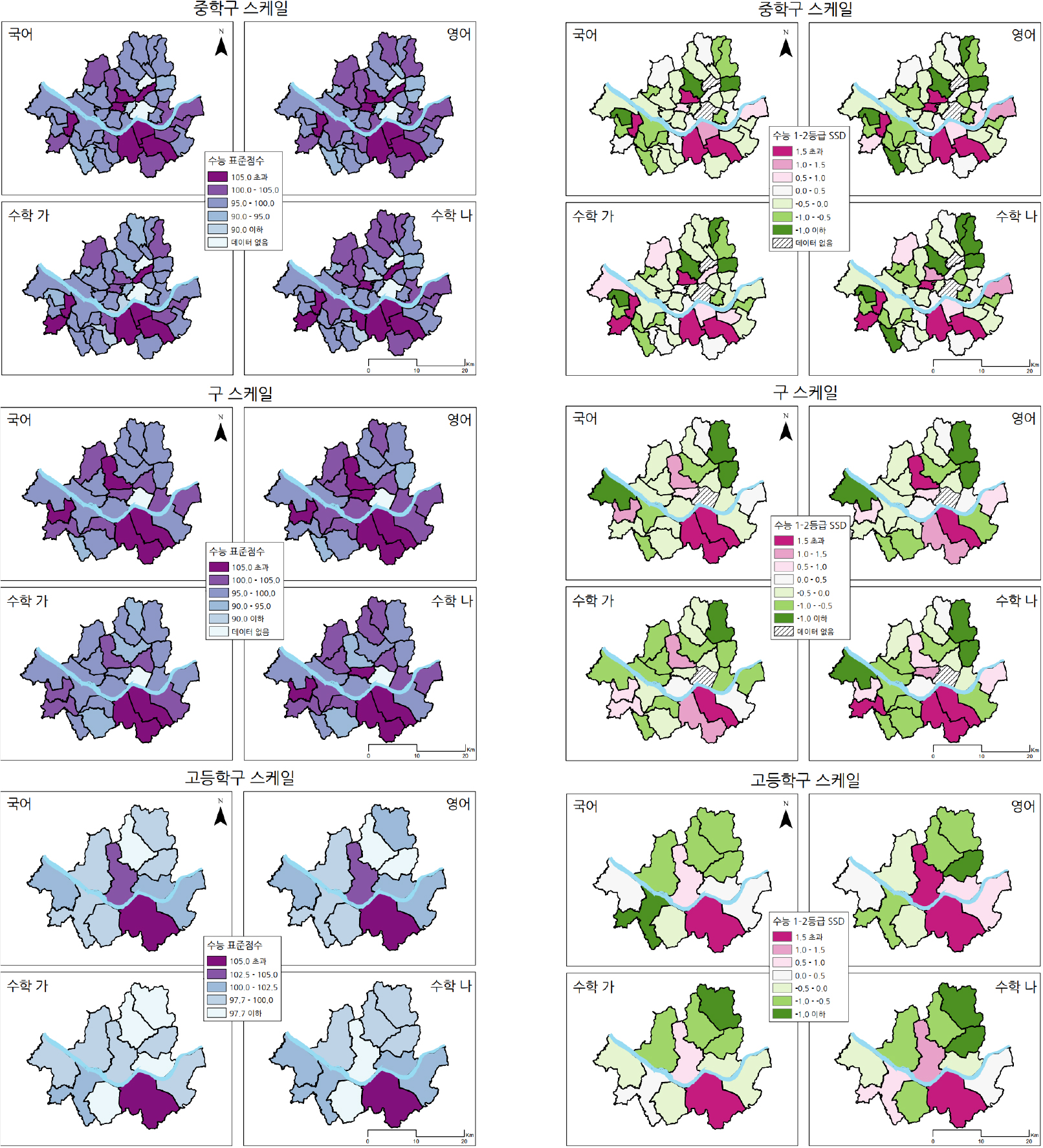
이에 먼저 각 과목별 표준점수를 측정스케일별로 지도화하면 그림 3과 같다. 이를 통해 크게 두 가지 정보를 확인할 수 있다. 첫 번째는 측정스케일별로 각 과목별 수능 표준점수를 지도화하였을 때 학업성과가 공간적으로 균등하게 분포하지 않는다는 것이다. 즉, 수능 표준점수가 높은 지역이 공간적으로 군집되어 있음을 확인할 수 있다. 특히 고등학구 스케일에서는 다른 지역에 비해 강남구-서초구 일대가 확연히 두드러지는 패턴을 보였다. 두 번째는 측정스케일별로 수능 표준점수의 공간적 패턴이 조금씩 상이하다는 것이다. 이는 MAUP과도 관련이 있는 것으로, 측정스케일 선택에 따라 연구결과가 달라질 수 있음을 시사한다. 이로써 측정스케일의 선택이 연구・분석에 있어 매우 중요한 과정임을 다시 한 번 확인할 수 있다. 그와 같은 양상은 측정스케일별 수능 1-2등급 학생의 비중(SSD)의 시각화를 통해서도 확인이 가능하다.
2) 거리에 따른 공간적 자기상관의 변화
(1) 공간적 코렐로그램 분석
공간적 코렐로그램은 거리에 따른 공간적 자기상관의 변화를 시각적으로 살펴보기에 매우 유용한 그래프이다. 이에 본 연구에서는 학교가 인접한 학교와 얼마나 유사한 학업성취도를 보이는지, 학교 간 거리가 멀어짐에 따라 그러한 경향성은 어떻게 변화하는지 살펴보기 위하여 공간적 코렐로그램을 활용하였다. 공간적 코렐로그램 분석은 티센폴리곤 수준에서 각 과목별 수능 표준점수와 1-2등급 학생 비중(SSD)에 대해 수행하였다. 이때 공간통계량은 모런 통계량을 활용하였으며, 코렐로그램 분석 결과는 표 3과 같다. 그림 4는 수능 표준점수를 활용한 과목별 코렐로그램(모런 통계량)을 나타낸 것이다. 우선, 수학 나를 제외하고 국어와 영어, 수학 가는 학교 간 거리가 멀어질수록 공간적 자기상관은 감소하는 패턴을 보였다. 이는 토블러(Tobler, 1970)의 ‘지리학의 제1법칙(The first law of geography)’에도 부합하는 결과이다. 다만, 통계적 유의성 측면에서 살펴보았을 때에는 영어와 수학 가에 대해서만 유의하게 나타났다. 영어 점수에 대해서는 두 번째로 인접한 학교까지, 수학 가 점수에 대해서는 첫 번째로 인접한 학교까지 통계적으로 유의미하게 수능점수가 유사한 것으로 나타났다. 이처럼 첫 번째 혹은 두 번째 공간지체(spatial lags)와 같이 좁은 범위에서 높은 상관관계가 나타나는 것은 전형적인 2차 효과(second-order effects)로 볼 수 있다(Bailey and Gatrell, 1995). 2차 효과는 공간 데이터 분석의 관점에서 공간적 의존성(spatial dependence)과 관련이 높으며, 네이버후드 효과 역시 1차 효과(first-order effects)보다는 2차 효과와 높은 관련이 있다(Lee, 2009; 2020). 그러나 수학 나의 경우, 학교 간 공간적 인접성에 따른 어떤 패턴도 찾기가 힘들었다. 수학과목은 유형(가형 혹은 나형) 선택에 따라 수능의 표준점수 혹은 등급의 유・불리성이 달라질 수 있어(이종학, 2011), 학생들은 상대적으로 점수 취득이 유리한 쪽으로 응시하기도 한다(신효진, 2007). 그러한 점이 반영되어 수학 나형의 코렐로그램은 다른 과목과 상이한 패턴을 보이는 것으로 추정할 수 있다. 각 학교의 상위 11%에 해당하는 1-2등급 학생의 비중(SSD)에 대한 코렐로그램 역시 표준점수의 코렐로그램의 패턴과 크게 다르지 않았다(그림 5). 이 역시 전형적인 2차 효과로 볼 수 있으며, 차이가 있다면 국어, 영어, 수학 가 과목에 대하여 표준점수의 코렐로그램 결과보다 첫 번째로 인접한 학교 간의 상관관계가 더 강하게 나타났다는 점이다.
표 3.
거리에 따른 표준 점수와 1-2등급(SSD)학생 비중의 공간적 자기상관 변화(모런 통계량)
| 점수 유형 | 표준점수 | 1-2등급(SSD) | |||||||
| 과목 | 국어 | 영어 | 수학 가 | 수학 나 | 국어 | 영어 | 수학 가 | 수학 나 | |
| lag | n | ||||||||
| 1 | (167) | 0.08(0.06) | 0.14(0.00)** | 0.09(0.03)* | -0.01(0.93) | 0.15(0.00)*** | 0.12(0.01)** | 0.16(0.00)*** | 0.06(0.16) |
| 2 | (167) | 0.02(0.45) | 0.06(0.05)* | -0.03(0.42) | 0.01(0.49) | 0.02(0.41) | 0.01(0.63) | -0.02(0.75) | -0.02(0.61) |
| 3 | (167) | -0.01(0.80) | -0.01(0.98) | -0.02(0.57) | -0.04(0.21) | -0.02(0.69) | -0.02(0.61) | -0.01(0.83) | -0.04(0.15) |
| 4 | (167) | -0.02(0.61) | -0.03(0.31) | 0.00(0.96) | -0.01(0.97) | -0.04(0.13) | -0.04(0.17) | -0.03(0.28) | -0.03(0.27) |
| 5 | (167) | -0.01(0.83) | -0.02(0.43) | -0.01(0.77) | -0.02(0.58) | 0.01(0.50) | 0.01(0.52) | 0.00(0.82) | 0.01(0.56) |
| 6 | (167) | 0.00(0.77) | 0.00(0.69) | 0.01(0.39) | 0.00(0.91) | -0.02(0.52) | -0.02(0.61) | -0.01(0.84) | -0.01(0.75) |
| 7 | (167) | -0.02(0.50) | -0.03(0.33) | -0.01(0.96) | 0.01(0.56) | -0.03(0.22) | -0.04(0.10) | -0.03(0.37) | -0.01(0.95) |
| 8 | (166) | 0.01(0.48) | 0.01(0.58) | -0.01(0.82) | 0.03(0.10) | 0.05(0.03)* | 0.06(0.01)* | 0.02(0.39) | 0.06(0.01)** |
| 9 | (159) | -0.05(0.23) | -0.06(0.09) | -0.05(0.21) | -0.01(0.78) | -0.04(0.32) | -0.02(0.76) | -0.02(0.63) | 0.06(0.05)* |
| 10 | (134) | -0.08(0.09) | -0.09(0.07) | -0.08(0.08) | -0.05(0.30) | -0.10(0.04)* | -0.08(0.09) | -0.09(0.05) | -0.07(0.16) |
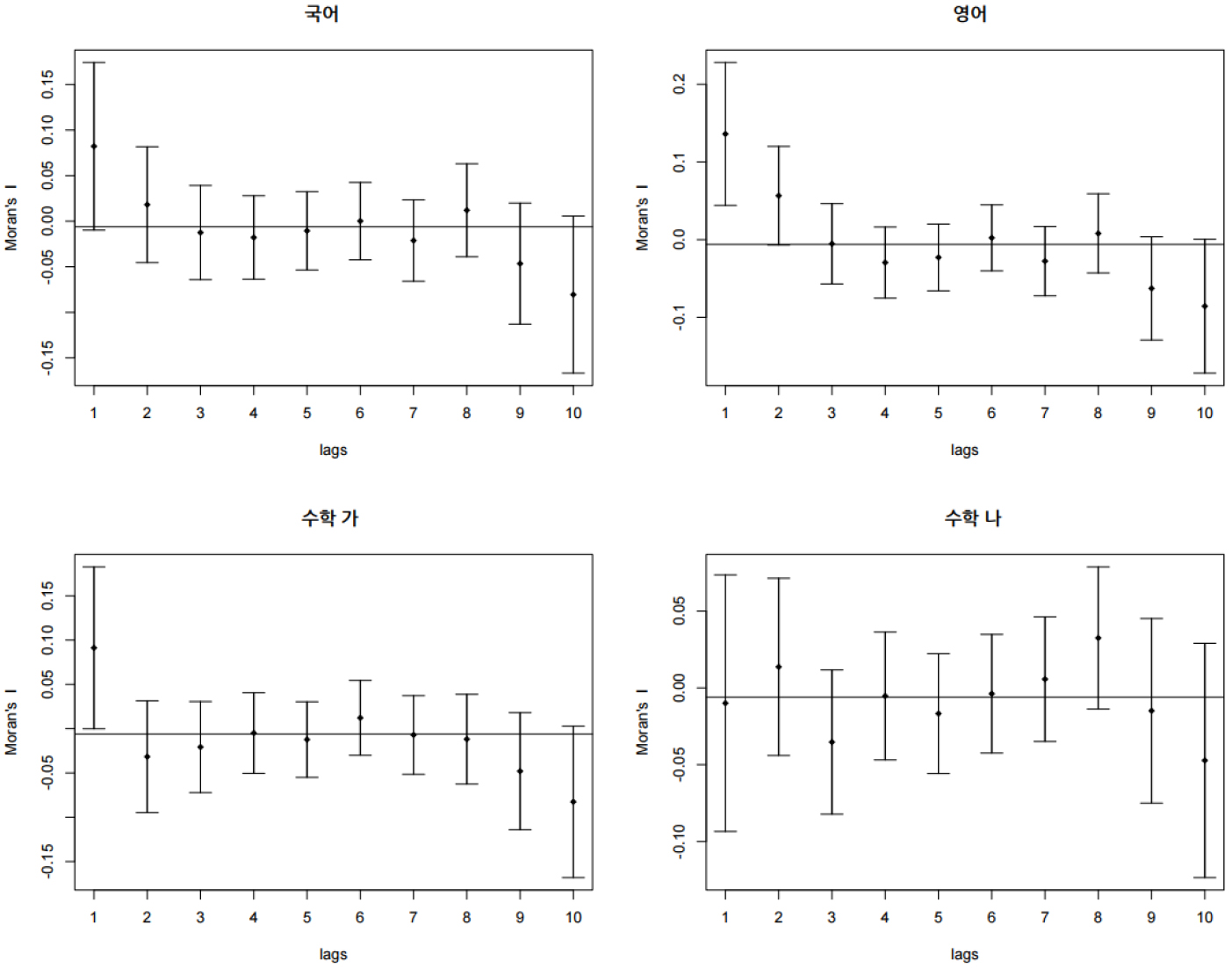
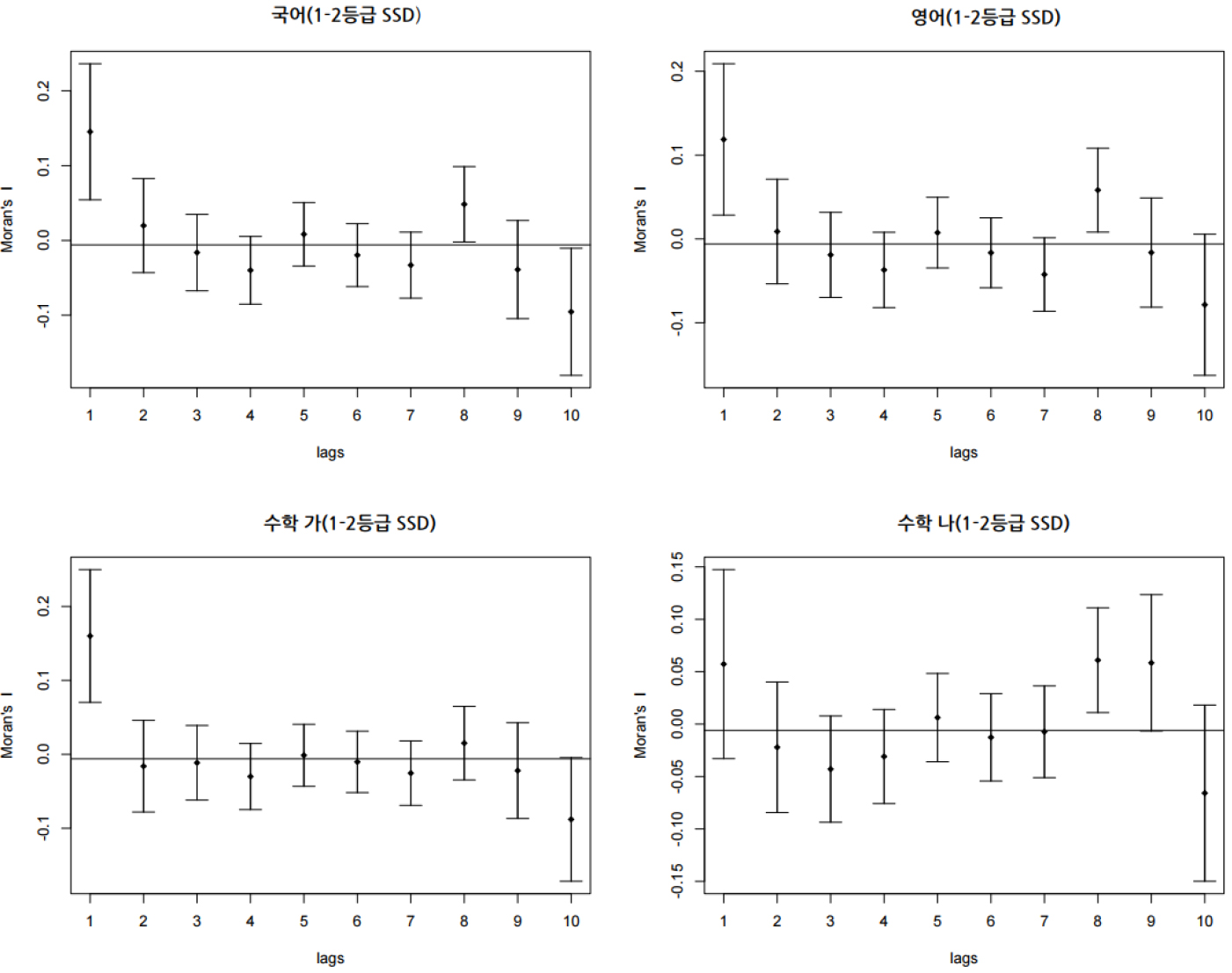
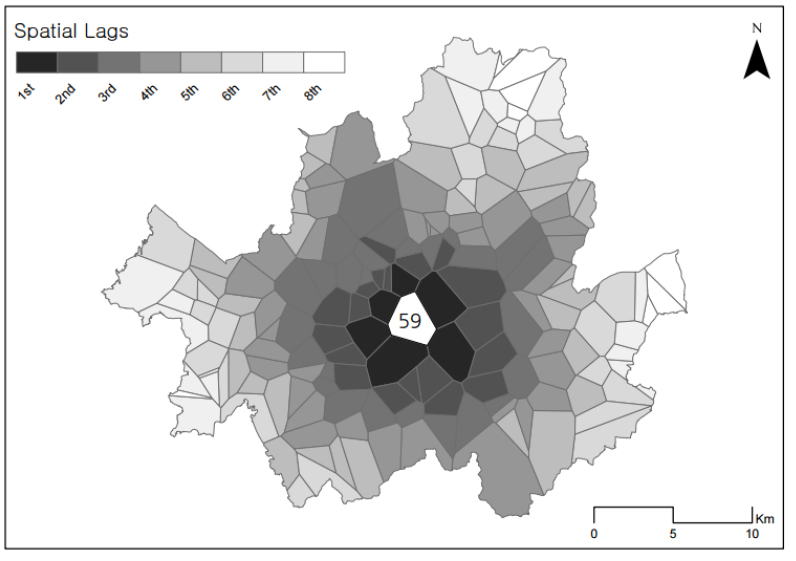
분석결과를 정리하면 과목별 통계량별로 다소간의 차이는 있었으나 표준점수와 1-2등급 비중 모두 첫 번째 혹은 두 번째로 인접한 티센폴리곤까지 양의 공간적 자기상관이 나타났다. 이는 앞서 밝혔듯이 2차 효과 즉, 네이버후드 효과로 볼 수 있으며(Lee, 2009; 2020), 이로써 작동스케일의 범위를 첫 번째 혹은 두 번째로 인접한 티센폴리곤까지로 규정할 수 있다. 예를 들어 영어표준점수 코렐로그램의 경우 두 번째로 인접한 티센폴리곤까지 양의 공간적 자기상관이 나타났는데, 이는 모든 티센폴리곤에 대하여 두 번째로 인접한 티센폴리곤까지를 작동스케일의 범위로 볼 수 있다는 것이다(Lee and Koo, 2017 참고). 티센폴리곤은 1번부터 167번까지 할당되는데, 이 중 59번 폴리곤에 대해 작동스케일의 범위를 예시하면 그림 6과 같다. 범례의 2nd 음영까지의 범위가 59번 티센폴리곤의 작동스케일이다.
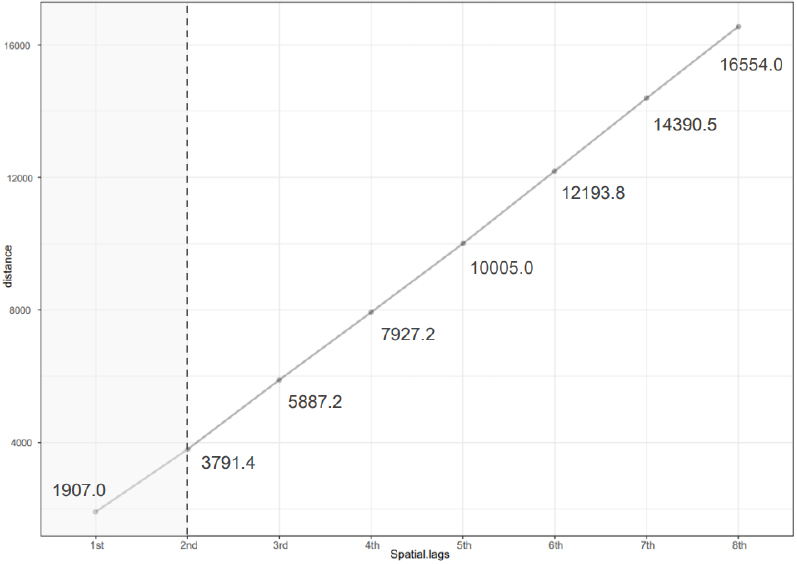
본 연구에서는 이와 같은 공간적 코렐로그램 분석결과를 실제 분석에서의 적용을 위하여 학교와 인접한 학교 간의 거리를 계산하였다. 이때 거리의 계산은 학교와 첫 번째로 인접한 학교 간의 평균 거리, 학교와 두 번째로 인접한 학교간의 평균거리, … 학교와 여덟 번째로 인접한 학교 간의 평균거리를 산출하였다. 그러나 학교와 번째로 인접한 학교들을 정의하기 위해서는 학교 간의 연접성(contiguity)규정이 필요하다. 통상 연접성 기반의 공간근접성행렬을 통해 정의할 수 있으나, 포인트 데이터의 경우 그러한 접근 방식의 적용이 어렵다. 이에 본 연구에서는 포인트 데이터를 티센폴리곤으로 변환하여 공간근접성행렬을 퀸으로 설정하고자 하였다. 즉, 포인트 데이터를 활용하여 학교 간 평균거리를 산출하되, 연접성 규정은 티센폴리곤으로 변환된 공간근접성행렬을 사용하는 것이다. 그렇게 계산된 학교 간의 평균 거리는 그림 7과 같다.
(2) 베리오그램 분석
다음으로, 작동스케일 탐색을 위해 베리오그램 분석을 수행하였다. 베리오그램 분석을 통해 산출된 상관거리의 값을 작동스케일로 활용하였는데, 이때 상관거리는 앞서 밝힌 바와 같이 공간적 자기상관이 더 이상 발생하지 않는 거리 범위를 의미한다(Lloyd, 2014). 학교 간 거리에 따른 점수의 유사성을 직관적으로 파악하기 위해서 실험적 베리오그램을 먼저 산출하고 이를 바탕으로 이론적 베리오그램을 적합하였다. 과목별 표준점수의 베리오그램 적합결과는 그림 8과 같다.
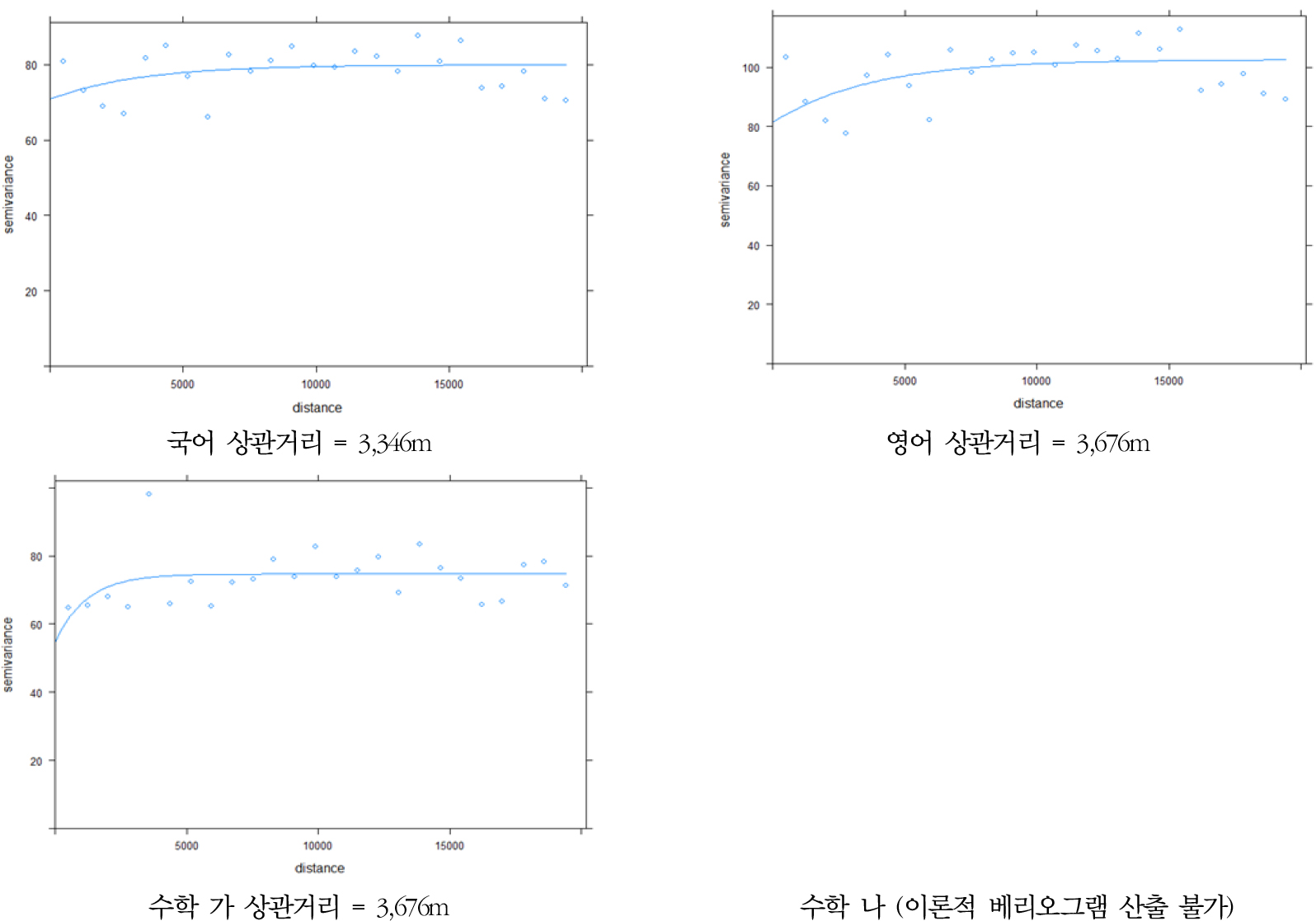
국어의 상관거리는 3,346m로 도출되었는데, 이는 각 학교 간의 거리가 3,346m가 되면 국어의 표준점수에 대해 더 이상의 공간적 자기상관이 발생하지 않음을 뜻한다. 다시 말해, 각 학교 간의 거리가 3,346m이내일 때 국어의 표준점수는 학교 간 유사한 경향을 보이며, 3,346m보다 학교 간 거리가 멀어지면 점수가 유사하지 않는 경향을 보이는 것이다. 영어와 수학 가의 상관거리 역시 국어의 상관거리와 유사한 값으로, 3,676m로 산출되었다. 이 역시 해석하면 학교 간의 거리가 3,676m이내일 때 영어와 수학 가의 표준점수가 유사하며, 학교 간 거리가 그보다 멀어질 때는 수능점수가 유사하지 않는 경향이 있음을 뜻한다. 수학 나의 경우, 이론적 베리오그램 적합(fitting)이 불가능하여 분석에서 제외하였다. 이처럼 수학 나에 대해서만 특이한 양상을 보이는 것은 앞서 밝힌 바와 같이 자연계열 학생들이 보다 높은 등급 혹은 표준점수 취득을 위해서 전략적으로 수학 나를 선택하는 경우가 많기 때문으로 추정할 수 있다(신효진, 2007 참고).
각 과목별 1-2등급 학생 비중(SSD)의 베리오그램 산출 결과는 그림 9와 같다. 우선, 국어와 영어의 1-2등급 학생비중(SSD) 베리오그램의 상관거리는 각각 2,354m, 2,519m로, 표준점수의 상관거리에 비해 더 좁게 산출되었다. 이는 1-2등급 학생 비중이 유사한 학교들이 표준점수가 유사한 학교들에 비해 상대적으로 더 좁은 범위에 군집되어 있음을 의미한다. 1-2등급 비중과 표준점수에 대한 베리오그램 분석 결과, 약간의 차이는 있었지만 학업성과가 유사한 학교들이 특정 공간 범위 내에 집중한다는 것을 다시 한번 확인할 수 있었다. 또 1-2등급 학생 비중(SSD)의 경우, 수학 나에 대해서도 베리오그램 적합이 가능했는데 이 점이 표준점수 베리오그램과의 차이점이다.
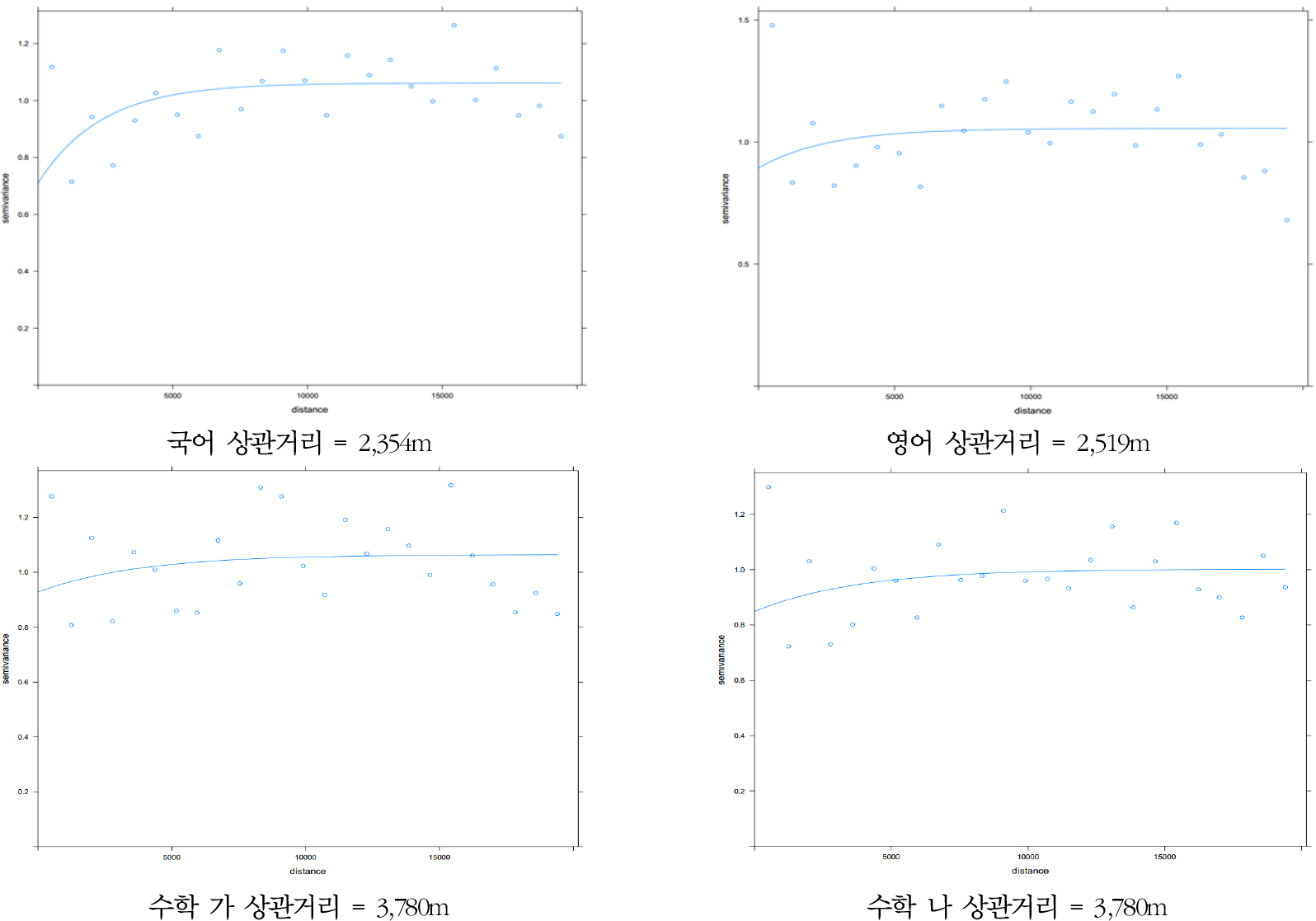
(3) 실제 분석에의 적용
그렇다면 앞서 분석한 작동스케일 탐색결과를 실제 분석에 어떻게 적용할 수 있을지에 대한 고민이 필요하다. 도출된 거리를 활용하여 임의의 공간단위를 생성할 수도 있으나, 본 연구에서는 분석의 용이함을 위하여 활용 가능한 세 가지 측정스케일(중학구, 시군구, 고등학구) 중 평균지름이 작동스케일과 가장 유사한 경우를 투입 측정스케일로 선정하고자 하였다. 그러나 각 측정스케일별로 공간단위의 형상(shape)이 모두 상이하므로 평균지름을 산출하는 작업은 쉽지 않았다. 이에 모든 공간단위의 면적을 산출한 후, 이를 원으로 가정하여 반지름을 산출하였다. 해당 과정을 수식으로 표현하면 수식 (5)와 같다. 반지름 산출 후에는 수식 (6)에 의해 각 측정스케일의 평균 지름을 산출하였다.
지역의 반지름, 지역의 면적, 지역의 지름, 해당 측정스케일의 평균 지름
이때 각 공간단위의 면적 산출을 위해서는 ArcMap의 Calculate Geometry 기능을 활용하였다. 이러한 과정을 통해 각 측정스케일별 지름을 계산한 결과 중학구는 3,955m, 구는 5,459m, 고등학구는 8,296m로 산출되었다. 산출된 측정스케일의 지름과 앞서 분석한 공간적 코렐로그램과 베리오그램의 결과를 비교해봤을 때(그림 8, 9 참고), 중학구 지름인 3,955m가 이들의 분석값과 가장 유사하였다. 이로써 세 가지 측정스케일 중 중학구 스케일이 교육성과 관련 연구의 작동스케일로써 활용가능하다고 정리할 수 있다. 이화정 등(2013)은 서울시 중학교의 특목고 진학률과 인근 초등학교의 순전입률 데이터를 활용하여 학교 선택의 공간성에 대해 연구한 결과, 중학구를 작동스케일로 규정할 수 있다고 밝힌 바 있다. 이는 본 연구에서 도출된 작동스케일과도 부합하는 결과이다.
4. 결론 및 제언
교육현상에 대한 네이버후드 효과 연구는 교육의 공간불평등 측면에서 점차 중요해지고 있다. 그러한 네이버후드 효과의 정량적인 측정과 관련해서는 여러 가지 방법론적 이슈가 있는데, 그 중에서도 네이버후드의 공간단위 설정의 문제는 네이버후드 효과가 특정 공간을 전제로 한다는 측면에서 매우 주요한 문제이다. 그럼에도 불구하고 네이버후드 효과 연구에서의 공간단위 선택에 대한 고려는 부족한 실정이다. 이에 본 연구에서는 다양한 공간통계기법을 활용하여 실제 교육성과에 대한 네이버후드 효과 분석 시 적용 가능한 네이버후드의 공간단위를 규정하고자 하였다. 네이버후드의 공간단위를 결정하기 위한 작동스케일 탐색은 주로 공간적 자기상관의 원리를 바탕으로 이루어졌다. 공간적 코렐로그램과 베리오그램 분석을 통하여 내부적으로는 공간적으로 동질적이고, 외부적으로는 이질적인 하나의 범위를 작동스케일로 가정하였다.
분석 결과는 다음과 같다. 첫 번째로 ESDA관점에서 측정스케일에 따라 기술통계치와 공간적 자기상관의 값이 어떻게 변화하는지 살펴보았다. 수능 표준점수와 1-2등급 비중의 기술통계치와 공간적 자기상관은 모두 측정스케일에 따라 상이하게 도출되었다. 이를 통해 학업성과에 대한 데이터에서도 MAUP의 영향은 나타나며, 측정스케일의 선택에 따라 연구결과가 상이해질 수 있음을 확인하였다. 즉, 연구목적에 맞는 적절한 측정스케일 선택의 필요성을 다시 한번 확인할 수 있었다.
두 번째로 작동스케일 탐색을 위해 거리에 따른 공간적 자기상관의 변화를 살펴보고자 공간적 코렐로그램과 베리오그램 분석을 수행하였다. 우선 공간적 코렐로그램의 경우, 과목과 점수 유형에 따라 다소간의 차이는 있었으나 표준점수와 1-2등급 비중 모두 첫 번째 혹은 두 번째 인접한 학교와 성적이 유사한 것으로 나타났다. 이처럼 좁은 범위에서 높은 상관관계가 나타나는 것은 전형적인 2차 효과, 즉 네이버후드 효과로 볼 수 있다. 이로써 공간적 코렐로그램 분석을 통해서 작동스케일은 첫 번째 혹은 두 번째 티센폴리곤으로 규정할 수 있었다. 이를 실제 분석에 적용하기 위해 공간 시차에 따른 학교 간 거리를 산출하였고, 그 결과 두 번째로 인접한 학교 간 거리는 3791.4m로 도출되었다.
세 번째로 과목별 점수 유형별 베리오그램 분석을 통해 공간적 자기상관이 더 이상 발생하지 않는 거리인 상관거리를 도출하였다. 표준점수에 비해 1-2등급 학생 비중에 대한 상관거리가 더 좁게 산출되었으나, 통상적으로 약 3,346 ~ 3,676m의 값을 가지는 것으로 나타났다. 이렇게 탐색한 작동스케일 결과와 활용 가능한 세 가지 측정스케일(중학구, 시군구, 고등학구)의 평균지름을 비교하여 가장 유사한 경우를 네이버후드로 선정하고자 하였다. 각 측정스케일별로 공간단위의 형상이 모두 상이하므로 모든 공간단위의 면적을 산출한 후, 이를 원으로 가정하여 지름을 산출하였다. 그 결과 중학구의 평균 지름 3,955m가 탐색한 작동스케일과 가장 유사함을 확인할 수 있었다. 이로써 교육성과에 대한 네이버후드 효과 연구를 위해서는 세 가지 측정스케일 중 중학구 스케일을 활용하는 것이 가장 적절하다는 결론을 내릴 수 있었다. 이는 교육현상 연구에서 중학구를 작동스케일로 규정할 수 있다고 밝힌 이화정 등(2013)의 연구 결과와도 일치한다.18)
본 연구는 대학수학능력시험 결과 데이터를 활용하여 측정스케일에 따라 연구결과가 달라질 수 있다는 것을 확인하고, 다양한 측정 스케일 중 연구에 적합한 작동스케일을 찾아가는 과정을 실증적으로 분석한데에 의의가 있다. 작동스케일 탐색과 네이버후드 효과 연구는 매우 중요함에도 불구하고, 두 분야 모두 국내 연구는 미진한 상태이다. 그러한 점을 감안하면 작동스케일 탐색을 통해 네이버후드의 공간단위를 산출한 것은 네이버후드 효과에 대한 시론적 연구로서 상당한 의의가 있다.19)
비단 네이버후드 효과 연구뿐만 아니라 지리학의 어떤 연구든 정량적인 분석을 진행한다면 필연적으로 특정 측정스케일을 선택할 수밖에 없으며, 그에 따라 연구결과 역시 달라질 수 밖에 없다. 그러한 측면에서 본 연구는 네이버후드 효과뿐만 아니라 다양한 주제의 지리학 연구에서 MAUP의 영향을 최소화할 수 있는 하나의 대안으로 제안될 수 있다. 그러나 MAUP의 프로세스 중 구획효과보다는 스케일효과에 보다 중점을 두어 구획효과에 대한 고려가 충분히 이루어지지 못하였다는 점은 앞으로 보완해야 할 부분 중 하나이다. 또한 분석의 편의성을 위하여 본 연구에서는 네이버후드의 범위를 시군구와 같은 행정구역 등 실제 존재하는 공간단위로 한정하였다. 그러나 실제로는 행정구역상의 경계와 실제 네이버후드의 경계는 일치하지 않을 수 있을 뿐만 아니라 네이버후드 간에도 범위가 상이할 수 있다(Lupton, 2003 참고). 추후 이와 같은 한계점을 보완하여 보다 현실에 부합하는 네이버후드 규정에 대한 후속 연구가 필요하다. 또한 학교급과 연령에 따라서도 네이버후드 효과가 달라질 수 있으므로 추후 다른 학교급과의 비교 연구 역시 필요한 바이다.
주
1) ‘강남 8학군’은 과거 1980년대 학군 개편 과정에서 등장한 용어로 현재는 존재하지 않는 명칭이다. 하지만 성기선의 2003년 연구를 비롯한 많은 연구에서 8학군을 “한국사회의 공간적・구조적 위계”를 상징적으로 나타내는 고유명사처럼 사용하고 있는 바(오제연, 2015), 본 연구에서도 해당 연구들을 인용할 때에는 원문의 표현을 그대로 인용하였다
2) 국내에서 네이버후드 효과는 이웃효과(예: 장수명, 2014), 동네효과(예: 곽현근, 2007; 2009; 김희윤・백학영, 2010), 근린사회 효과(김형용, 2013) 등으로 번역되어 사용되고 있다. 그러나 이들의 사전적 의미는 다소 협소한 범위의 공간적 범위를 규정하다고 볼 수 있다. 예를 들어 ‘이웃’은 “나란히 또는 가까이 있어서 경계가 서로 붙어 있음 혹은 가까이 사는 집 또는 그런 사람”을 의미하며, ‘근린’은 “가까운 이웃 혹은 가까운 곳”을 의미한다(국립국어원 표준국어대사전). 이는 Kearns and Parkinson(2001)이 분류한 세 가지 의미의 네이버후드 중 첫 번째 네이버후드 수준인 생활영역(Home area)에 가깝다고 볼 수 있다. 생활영역은 단순 거주지에서 5 ~ 10분 거리내의 공간적 범위로 규정되는데, 본 연구에서는 교육성과에 영향을 미치는 네이버후드를 그와 같이 규정하기는 어렵다고 판단되어 원문 그대로 ‘네이버후드’ 혹은 ‘네이버후드 효과’ 명명하였다.
3) 이지현(2019)은 네이버후드 효과라는 용어를 직접적으로 사용하지 않았지만, 네이버후드 효과 발생의 메커니즘으로도 볼 수 있는 ‘지역사회 집합적 효능(neighborhood collective efficacy)’와 학교폭력가해행동과의 관련성을 분석하였다.
4) 작동스케일이란, “특정한 공간 프로세스가 작동하는 스케일(신정엽, 2005)”로, 서로 다른 공간 프로세스는 서로 다른 스케일에서 작동한다는 원리를 기반으로 한다(Lam and Quattrochi, 1992).
5) MAUP은 스케일과 합역양식에 따라 야기되는 문제로(Longley et al., 2005; 이상일 등 역, 2009), 공간데이터 분석의 가장 고질적인 문제 중 하나로 여겨진다(Openshaw, 1984; Wong, 2009; Lee et al., 2019 참고). MAUP의 프로세스는 스케일효과(scale effect)와 구획효과(zoning effect)로 구분할 수 있는데, 본 연구는 구획효과보다는 스케일효과에 보다 중점을 둔다.
6) Kwan(2018)은 기존 네이버후드 효과 연구가 주로 거주지 기반으로 이루어져온 것에 대해 비판하며, 맥락의 다차원적인 측면, 시간의 복잡성 등을 고려해야 함을 주장하였다. 본 연구에서의 네이버후드 효과가 단순히 '거주지 효과'를 의미하는 것이라면 분석의 대상을 일반고로 국한해야 하겠지만, 다차원적인 맥락을 고려할 때 학교의 유형이 다르더라도 학생들은 오랜 기간 학교 주변에 머물기 때문에 학교 주변의 환경은 학생들의 선택이나 행동에 영향을 미치기에 충분하다고 판단하였다. 그럼에도 불구하고 각 학교별로 선발시기와 교육과정 등이 다소 상이하므로 후속연구를 통해 이들 차이에 따라 학교효과 및 네이버후드 효과 등이 어떻게 달라지는지 살펴볼 필요가 있다.
7) Z점수 = (수험생의 원점수) - (수험생이 속한 영역(과목)의 평균) / 수험생이 속한 영역(과목)의 표준편차 (표준점수) = (Z점수) × (해당영역 (과목)의 표준편차) + (평균)
8) 2018학년도 대학수학능력시험 결과 역시 에듀데이터에서 제공받을 수 있으나, 2018학년도부터 영어 영역의 평가방식이 절대평가로 전환됨에 따라 백분위와 표준점수가 제공되지 않을 뿐만 아니라 등급 산출 방식도 다른 과목과 상이하여 2017학년도 데이터를 사용하였다(교육부 홈페이지 참조).
9) 티센폴리곤은 가장 가까운 모든 인접한 점을 직선으로 연결한 후, 그 연결선을 수직으로 이등분하여 제작된다(Griffith, 1987).
10) 본 연구에서 활용 가능한 학교의 수는 167개인데 반하여 서울시의 행정동은 총 424개로, 각 행정동마다 학교 데이터가 1개 이상 할당되기는 힘들다. 이에 행정동은 분석에서 제외하였다.
11) 중학구와 고등학구의 설정 및 고시방법에 대해서는 「초・중등교육법 시행령」제68조, 제84조에서 각각 고시하고 있다. 학구도 안내서비스에서는 2016년 10월부터 학구 설정 고시내역을 공지하고 있는데, 2016년 10월부터 2017년 3월까지 서울지역의 중학구와 고등학구의 변경사항은 없다. 이에 본 연구에서는 분석을 위해서 해당 데이터를 사용하였다.
12) 그 이후 네이버후드 개념은 1972년 Suttles의 연구를 통해 세련화를 거쳤고, 현재 다양한 논의가 진행되고 있다. 특히 현재 네이버후드 내부의 이질성(heterogeneity)에 대한 고려 역시 필요하다는 논의가 진행되고 있으나(Small and Feldman, 2012 참고), 실증적 연구의 편의성을 위하여 내부적인 동질성을 가정하고 작동스케일을 탐색하였다.
13) 공간근접성행렬(SPM)은 관측개체들간의 근린관계를 정의해주는 것으로, 국내에서는 근린가중치행렬(박현수・김찬호, 2007), 공간가중행렬(이창로・박기호, 2013) 등 다양한 용어로 사용되고 있다. 그러나 실질적으로는 행-표준화를 실시하였을 때에만 SPM의 요소가 ‘가중치’의 의미를 지니므로(이상일 등, 2015), 가중치행렬은 공간근접성행렬에 비하여 협소한 의미를 지닌다고 볼 수 있다. 이에 본 연구에서도 SPM의 용어를 사용하고자 한다.
14) 연접성에 기반한 공간근접성행렬은 크게 루크(rook), 비숍(bishop), 퀸(queen)으로 구분할 수 있는데, 그 중에 퀸은 지점을 중심으로 점과 변으로 연결되어도 모두 이웃을 간주하는 방식이다(이상일 등, 2015 참조).
15) 베리오그램을 2로 나눈 것을 반베리오그램(semi-variogram)이라고 하나, 통상적으로 구분 없이 베리오그램이라 부르기도 한다. 제시된 수식은 반베리오그램의 수식이다.
16) 전수데이터 혹은 추출된 샘플이 달라지는 경우, 결과가 상이하게 도출될 수 있다는 한계가 있다. 추후 시뮬레이션 연구 등을 통한 면밀한 검토가 필요하다.
17) 실험적 베리오그램은 선형 모형(linear model), 구형 모형(spherical model), 지수 모형(exponential model), 가우시안 모형(Gaussian model) 등 다양한 모형으로 모델링하여 이론적 베리오그램을 산출할 수 있다.
18) 이는 서울시를 대상으로 하였을 때, 적용 가능한 것이고 다른 지역에 대해 분석한다면 그 지역의 맥락에 따라 상이한 결과가 도출 될 수 있다.
19) 자세한 내용은 이소영(2020) 참고.
