

1. 서론
2. 도로추출을 위한 데이터 제작
1) 자료 수집 및 전처리
2) 마스킹 영역 삽입
2. Model 및 훈련
1) 비교 모형
2) 훈련 설정
3) 평가 지표
3. 도로 추출 결과
4. 결론 및 시사점
1. 서론
원격탐사 분야에서 도로 정보 추출 자동화는 주된 연구 주제로, 자율주행(Yang et al., 2020), 네비게이션과 지리정보 데이터베이스(Wei et al., 2020), 스마트 도시 건설(Chen et al., 2021; Tan et al., 2020), 도로 네트워크 생성(Senthilnath et al., 2020) 등 여러 분야에서 활용되기 때문에 그 가치가 높다. 전통적인 도로 추출 방법은 일반적으로 도로의 질감, 기하학적, 광학적 특성을 기반으로 자동, 반자동 방식을 통해 연구되고 있다(Barzohar and Cooper, 1996; Kass et al., 1988; Lin et al., 2008, 2012; Melgani and Bruzzone, 2004; Mena, 2003; Park 2001; Yager and Sowmya, 2003). 하지만 이러한 전통적인 방법들은 대규모의 데이터를 처리할 때 많은 시간과 자원이 필요하며, 특히 도로와 같은 지표 객체를 추출하기에 그림자, 나뭇가지 등의 노이즈가 많은 원격탐사 영상을 효과적으로 분할하기 어렵다. 이러한 그림자 효과는 위성영상과 항공사진에서 객체를 추출하는 과정에서 지속적으로 문제가 되어왔으며, 객체의 유형에 따라 그 해결방법도 다양하게 제시되어 왔다(Kim and Oh, 2020; Park et al., 2017; Yang et al., 2024; Ye, 2017). 위성영상에서 노이즈로부터 객체를 효율적으로 분할하기 위한 방법으로 고해상도 영상을 분석하기 위한 딥러닝 기반 연구가 활발히 진행되고 있다.
딥러닝 기반의 도로 정보 추출은 주로 의미론적 분할(Semantic Segmentation) 기법으로 수행되며 모형이 영상으로부터 도로의 시각적 특징을 학습하여 도로와 비도로로 이진 분류한다. 그러나 원격탐사 영상에서는 건물, 나무 등의 객체가 도로를 가리는 현상이 발생한다(Chen et al., 2022). 이러한 가림 현상으로 인해 도로가 시각적으로 다른 객체와 겹쳐져 단편화되거나 분리된 형태로 나타난다. 이러한 문제는 모형이 도로의 시각적인 특성과 문맥적인 정보에 대한 학습을 방해하여 도로 추출 모델의 성능 저하를 유발한다. 성능 저하의 사례로는 도로가 단절된 형태로 출력되거나 형태가 왜곡되는 등 도로의 위상학적, 구조적인 특징이 손상되는 경우가 발생한다. 몇몇 연구들은 가림 현상으로 인한 성능 저하를 줄이기 위한 방법으로 어텐션 메커니즘을 사용하여 예측 방식에 변화를 주는 방식을 사용하였다(Chen et al., 2021; Li et al., 2020; Mei et al., 2021; Wang et al., 2021; Wei et al., 2020). 이미지 분할을 위해 어텐션 메커니즘은 이미지의 각 픽셀이나 패치가 서로 어떻게 연관되는지를 학습하여 중요한 시각적 정보를 강조한다. 어텐션 처리과정은 인코딩과 디코딩으로 구분되는데, 인코더는 이미지의 모든 부분 간의 관계를 파악하여 각 픽셀의 문맥적 정보를 풍부하게 표현한다. 디코더는 이러한 정보를 활용하여 각 픽셀이 속하는 객체나 영역을 정확히 구분하게 된다.
또 다른 방법으로 데이터 증강을 통해 모델의 학습 데이터를 풍부하게하여 성능 저하를 방지하는 연구가 수행되고 있다(Babaali et al., 2022; Chen et al., 2023; Feng et al., 2021; Guo and Zhou, 2023). 데이터 증강은 모델의 일반화 성능을 향상시키기 위해 학습 데이터의 다양성을 증가시키는 훈련 전략으로, 부분적으로 가려진 도로의 추출 성능을 높일 수 있는 방법이다(Guo and Zhou, 2023). 대이터의 증강을 위해 초기 학습 데이터를 회전, 대칭과 같은 기하학적 변환, 밝기와 대비 조정과 같은 강도 변환, 이미지의 일부를 검은색으로 마스킹하는 정보 삭제 변환 등의 다양한 방법이 시도되고 있다. 그중 정보 삭제 방법은 입력 이미지의 일부 영역 값을 제거하는 방식으로 모형이 값이 없는 영역을 학습하며 견고한 예측 모형을 제작할 수 있다(Chen et al., 2020; DeVries, 2017; Zhong et al., 2020). 이러한 기법들은 입력 이미지에서 임의의 영역을 삭제하거나 새로운 값으로 대체하여 모델이 여러 형태의 가림 현상을 학습할 수 있도록 돕는다. 그러나 도로 추출에 사용되는 데이터는 도로 픽셀에 비해 비도로 픽셀의 비율이 매우 높아 데이터 불균형 문제가 존재한다. 이로 인해 무작위로 영역을 삭제하거나 마스킹을 적용할 경우, 비도로 영역에 마스킹 영역이 과도하게 할당될 수 있으며, 이는 모델이 도로 영역의 주요 특징을 학습하는 데 어려움을 초래할 수 있다.
따라서 본 연구에서는 도로의 구조적 특성을 유지하기 위해 마스킹 데이터를 학습한 AI 기반 분할 모형을 활용하여 도로 지역을 추출하는 방법을 제시하고자 하였다. 이를 위해 기존의 데이터 증강법 중 정보 삭제 방법을 확장하여 AI 기반 의미론적 분할 모델에 도로의 특성과 주요 특징을 학습시켜 도로의 연결성을 향상시키고 예측 도로와 실제 도로의 구조적인 유사성을 높이고자 하였다. 특히, 도로의 가림 현상이 가장 많이 발생하는 경계 부근에만 마스킹 영역을 삽입하여, 모델이 도로의 경계와 주요 구조적 특징을 더욱 효과적으로 학습할 수 있도록 하였다. 또한 데이터의 다양성을 확보하기 위해 마스킹 영역별 크기도 무작위로 설정하여 크기와 위치가 임의로 변동하는 마스킹을 통해 다양한 가림 상황을 모델이 학습할 수 있도록 하였다. 마스킹 데이터의 적용 효과를 평가하기 위해, 전체 학습 데이터셋에서 마스킹 데이터를 섞은 비율을 다르게 설정하여, 마스킹 데이터의 비율 변화가 모델 성능에 미치는 영향을 측정하고자 하였다. 이를 위해 딥러닝 모형으로 U-Net, SegNet, SegFormer를 사용하였으며 도로 분류 결과의 구조적인 성능을 측정하기 위해 픽셀 기반의 평가 지표들과 함께 Average Path Length Similarity(APLS)와 Structural Similarity Index(SSIM)을 사용하였다.
2. 도로추출을 위한 데이터 제작
본 연구의 공간적 범위는 대한민국 서울시이며 정사영상과 수치지형도를 활용하여 입력 이미지와 정답 이미지를 제작하였다. 학습데이터로는 입력 이미지와 정답 이미지 쌍으로 편집하여 사용하였다. 딥러닝 기반 의미론적 분할 작업 모형의 도로추출 결과를 비교하기 위해 본 연구에서는 4가지의 CNN 기반의 모형과 1가지의 트랜스포머 모형을 선정하였다.
1) 자료 수집 및 전처리
본 연구에서 사용한 데이터는 국토정보지리원(https://www.ngii.go.kr/kor/main.do)에서 제공하는 서울시 정사영상을 입력 이미지로 사용하였으며 수치지형도로 annotation 데이터를 제작하여 각 이미지와 annotation 데이터가 대칭되도록 하였다. 정사영상과 수치지형도는 2021년에 촬영 및 제작된 자료이다. 각 자료의 제원은 표 1과 같으며 서울시 전역을 포함하기 위해서는 137장이 필요하지만 도로의 비율이 적은 산지 개활지 등을 제외한 83장의 정사영상만을 분석 자료로 사용하였다. 국토지리정보원에서 제공하는 정사영상에는 좌표계가 설정되지 않은 상태로 제공되기 때문에 지리참조 작업을 통해 Korea_2000 중부원점 좌표계로 설정하였다. 수치지형도에서는 도로 경계 파일을 사용하였다.
표 1.
사용 데이터 제원
| 정사영상 | 연속수치지형도 | |
| 촬영 지역 | 서울시 | |
| 촬영 시기 | 2021년 | |
| 공간 해상도 | 25cm | |
| 축척 | 1:5000 | |
| 좌표계 | Korea_2000_Korea_Central_Belt_2010 | |
| 크기 | 11,508 * 9,252 | - |
의미론적 분할 작업을 수행하기 위해서는 정사영상과 함께 실제 픽셀에 도로의 값을 의미하는 annotation 자료가 필요하다. 수치지형도를 활용하여 2가지 과정을 통해 정답 데이터를 제작하였다. 첫 번째로 정사영상으로부터 연속수치지형도의 값을 기반으로 도로에 해당하는 영역과 도로가 아닌 영역을 추출하였다. 두 번째로는 추출한 정사영상에서 도로에 해당하는 영역과 도로가 아닌 영역에 각각 특정한 값을 설정하였다. 같은 작업을 83장의 정사영상에 수행하여 그림 1과 같은 정답 데이터를 제작하였다.
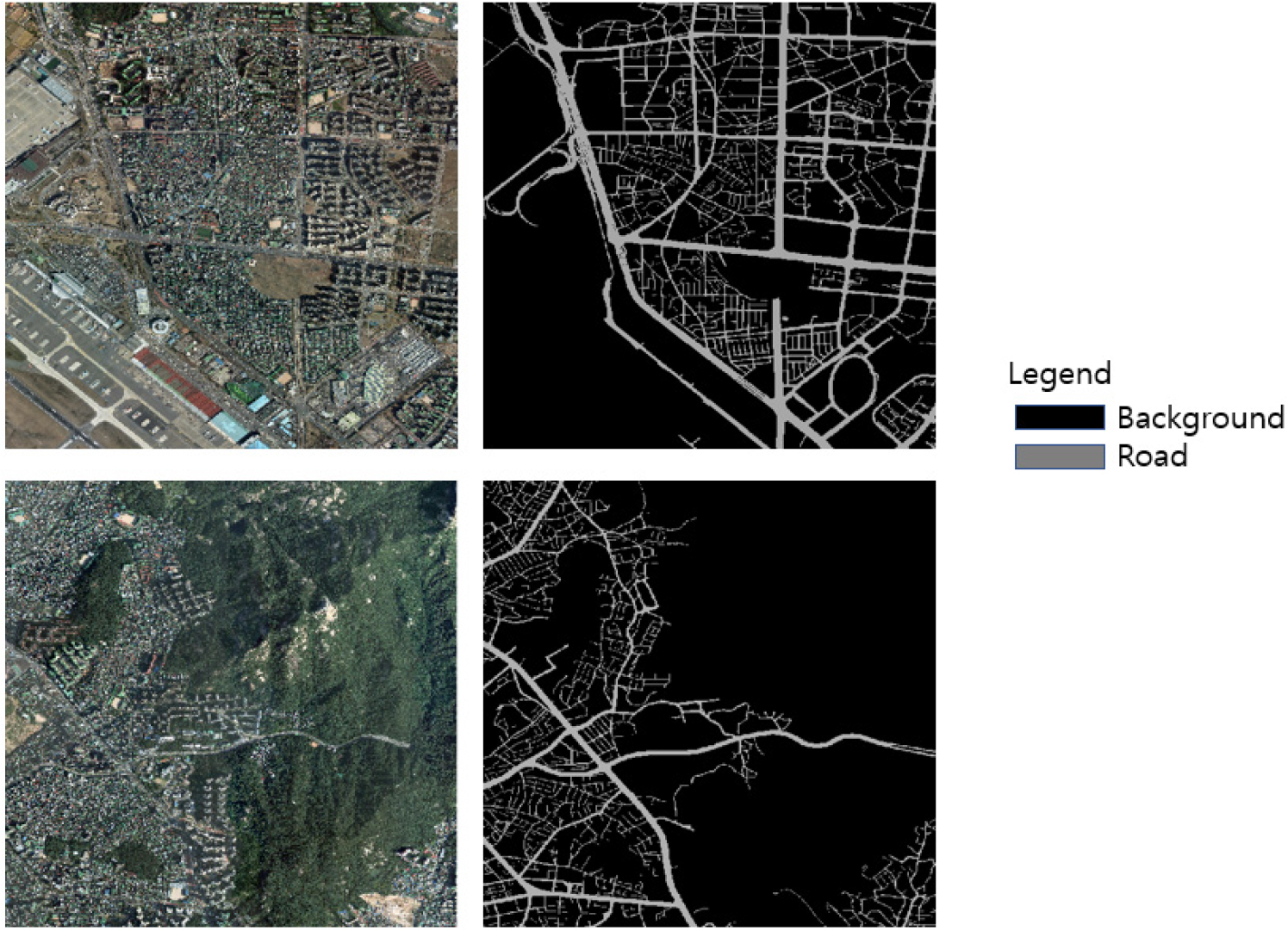
그림 1과 같이 생성한 83쌍의 정사영상과 annotation 자료를 512*512의 크기로 편집하여 모델 훈련을 위한 26,305쌍의 입력 자료를 제작하였다(그림 2). 이후 모형의 일반화 능력을 평가할 수 있으며 과적합을 방지하기 위해 전체 입력 자료 쌍들을 훈련 데이터, 검증 데이터, 평가 데이터로 나누어 훈련 데이터는 15,783쌍, 검증 데이터와 평가 데이터는 각각 5,261쌍의 데이터로 구성하였다.

2) 마스킹 영역 삽입
가로수나 도로 주변 건물의 그림자 등은 도로를 가려서 비도로 영역 간의 경계를 모호하게 만들어 모델이 도로를 정확히 인식하는 데 어려움을 겪게 한다. 이러한 문제를 보완하기 위한 무작위 위치에 마스킹 영역을 추가하는 방식은 도로의 특징과 연결성을 충분히 반영하지 못할 수 있다. 따라서 도로 경계 부분에만 마스킹 영역을 추가함으로써 모델이 배경 영역이 아닌 도로 영역의 특징을 효과적으로 학습하도록 유도하였다. 도로 경계와 주변 객체의 일부를 동시에 가리는 방식을 통해 도로 경계의 왜곡이나 누락을 방지하고 가림 현상으로 인한 추출 오류를 줄일 수 있는 효과를 기대하였다. 마스킹 데이터를 제작하는 순서는 그림 3과 같이 먼저 정답 데이터를 기반으로 도로의 외곽선을 추출한다. 도로의 외곽선 추출 작업에는 캐니 엣지 검출기(Canny Edge Detector)를 사용하였다. 이후 입력 이미지에 정답 이미지로부터 검출된 외곽선의 위치정보를 기반으로 무작위 위치와 크기의 마스킹 영역을 삽입한다.

2. Model 및 훈련
1) 비교 모형
CNN과 트랜스포머 기반의 의미론적 분할 모형들의 도로추출 결과를 비교하기 위해 총 3개의 모형을 제작하였다. CNN 기반 모형의 특징은 합성곱 연산을 사용하여 입력 이미지로부터 특징을 추출하여 예측에 활용하고 트랜스포머 기반 모형은 어텐션 메커니즘으로 입력 이미지의 분석을 수행하며 본 연구에서는 의미론적 분할 작업을 수행하기 위해 응용된 모형들을 선정하였다. CNN 기반의 모형은 U-Net, SegNet을 활용하였으며 트랜스포머 기반 모형은 SegFormer를 활용하였다.
2) 훈련 설정
인공 신경망들의 훈련 성능 비교를 위해 동일한 분석 환경과 하이퍼파라미터 설정을 적용하였다. 주요 하이퍼 파라미터로 Epoch는 300으로 설정하였으며 Learning Rate는 0.005, Loss Function은 Binary Cross Entropy, Optimizer는 Adam을 활용하였다. 마스킹 데이터의 적용 효과를 측정하기 위해 전체 데이터셋에서 마스킹 데이터의 비율을 달리하여 모델을 훈련하였다. 마스킹 영역이 없는 원본 데이터로만 구성된 학습 데이터셋(Masking Data 0%), 마스킹 데이터와 원본 데이터를 1:1로 혼합한 데이터셋(Masking Data 50%), 그리고 마스킹 데이터로만 구성된 데이터셋(Masking Data 100%)을 사용하여 훈련 결과를 비교하였다.
3) 평가 지표
도로 추출 모델의 성능을 평가하기 위해 픽셀 기반 평가 지표와 구조 기반 평가 지표를 활용하여 성능을 측정하였다. 먼저 픽셀 기반 평가 지표는 모델이 도로를 얼마나 정확하게 식별하고 추출했는지를 픽셀 단위에서 평가하는 방법으로, 정확도, 정밀도, 재현율, F1-Score, mIoU를 활용하여 도로 추출 성능을 측정하였다. 또한 도로 추출 결과의 연결성 및 구조적 특성을 평가할 수 있는 구조 기반 평가 지표를 추가하여 모형의 성능을 보다 포괄적이고 깊이 있게 분석하였다. 구조 기반 평가에 사용한 지표는 APLS와 SSIM이다.
픽셀을 기반으로한 평가지표는 혼동행렬을 기반으로 평가하며 예측 결과와 정답 이미지를 비교하여 산출된다. 정확도(수식 1)는 전체 픽셀 중에서 모델이 얼마나 정확하게 예측했는지를 나타내는 지표로, 모든 클래스에 대해 올바르게 예측된 픽셀의 비율을 의미한다. 정밀도(수식 2)는 특정 클래스에 대해 모델이 얼마나 정확하게 예측했는지를 측정하는 지표로, 예측한 True 클래스 중에서 실제로 True인 비율을 뜻한다. 재현율(수식 3)은 실제로 True인 클래스를 모델이 얼마나 잘 예측했는지를 나타내며 전체 True값 중에서 얼마나 많은 True값을 정확히 예측했는지를 측정하는 지표이다. F1-Score는 정밀도와 재현율의 조화평균을 통해 두 지표 간의 균형을 고려한 종합적인 성능을 측정하는 지표이며 <수식 4>와 같다. IoU(Intersection over Union) 값은 모델의 예측과 실제 참값 간의 겹치는 부분을 평가하는 지표로, 예측 영역(Prediction)과 실제 영역(Target)이 얼마나 일치하는지를 측정한다(수식 5).
여기서, TP(True Positive)는 실제 도로 픽셀에 대해 예측 도로 픽셀이 맞게 분류한 픽셀의 수를 뜻하고 TN(True Negative)은 실제 배경 픽셀에 대해 예측을 배경 픽셀로 맞게 분류한 수를 뜻한다. FN(False Negative)은 실제 도로 픽셀에 대해 배경 픽셀로 예측한 픽셀의 수이며 FP(False Positive)는 실제 배경 픽셀을 도로 픽셀로 예측한 픽셀의 수를 뜻한다.
APLS는 도로 네트워크의 구조적 유사성을 측정하기 위해 제안된 그래프 이론 기반의 지표이다(Van Etten et al., 2018). 이를 구하는 과정은 <수식 6>과 같다. 먼저 출력 이미지와 정답 이미지의 도로를 노드와 링크로 변환하여 네트워크화한다. 이후 네트워크를 구성하는 모든 경로에 대한 길이를 비교하여 유사도를 측정한다. 아래의 수식에서 은 고유한 경로의 수를 의미하며 는 지점에서 지점까지의 링크화된 경로의 길이를 뜻하며 은 정답 이미지에서의 지점에서 까지의 거리를 뜻한다. 두 그래프 간의 경로 길이 차이를 계산하고 누락된 경로에 대해 패널티를 부여하여 유사도를 측정한다. 예측 결과에서 도로가 단절되거나 왜곡된 경우 이를 노드와 링크로 변환하였을 때 네트워크를 구성하면 경로의 수, 위치 등이 달라질 수 있으며 이러한 경우 APLS 값이 저하된다.
SSIM(Structural Similarity Index Measure)은 이미지 간의 유사성을 밝기(luminance), 대비(contrast), 그리고 구조(structure)라는 세 가지 주요 측면에서 비교한다(Wang et al., 2004). SSIM은 <수식 7>로 계산되며 밝기는 정답 이미지와 출력 이미지의 픽셀 평균값을 통해 계산된다(수식 8). 대비의 연산식은 <수식 9>와 같으며 각 이미지의 표준편차로 측정된다. 마지막으로 구조는 두 이미지 간의 공분산을 계산되며 <수식 10>과 같다. 이러한 세 가지 요소는 각각 비교 함수로 측정된 후 최종 SSIM 값을 산출하기 위해 결합된다.
3. 도로 추출 결과
마스킹 데이터의 비율을 다르게 설정한 데이터 세트별 도로 추출 결과는 그림 4와 같다. (A), (B), (C)는 각각 U-Net, SegNet, SegFormer로 예측한 결과이다. 먼저, 원본 데이터(Masking Data 0%)만을 사용하여 학습시킨 모델의 도로 예측 결과는 마스킹 데이터를 활용한 경우에 비해 도로가 단절된 형태로 출력되는 경향을 보였다. 또한, 도로와 비도로의 경계 부근에서의 예측이 비교적 불균일하게 나타났다. 반면에 마스킹 데이터를 활용한 결과에서는 도로의 연속성이 개선되어 도로 단절 현상이 비교적 완화되었다. 마스킹 데이터가 도로 영역에 집중할 수 있도록 유도함으로써 모델이 도로를 학습할 때 중요한 구조적 특징을 잘 반영한 것으로 보인다. 또한 도로와 비도로의 경계에서 형태가 왜곡되던 현상이 줄어든 것으로 확인되었다. 이러한 결과는 마스킹 데이터를 적용함으로써 예측 모델이 도로의 구조적인 특징을 학습하여 경계 부근에서의 일관된 예측을 수행한 것으로 보인다.
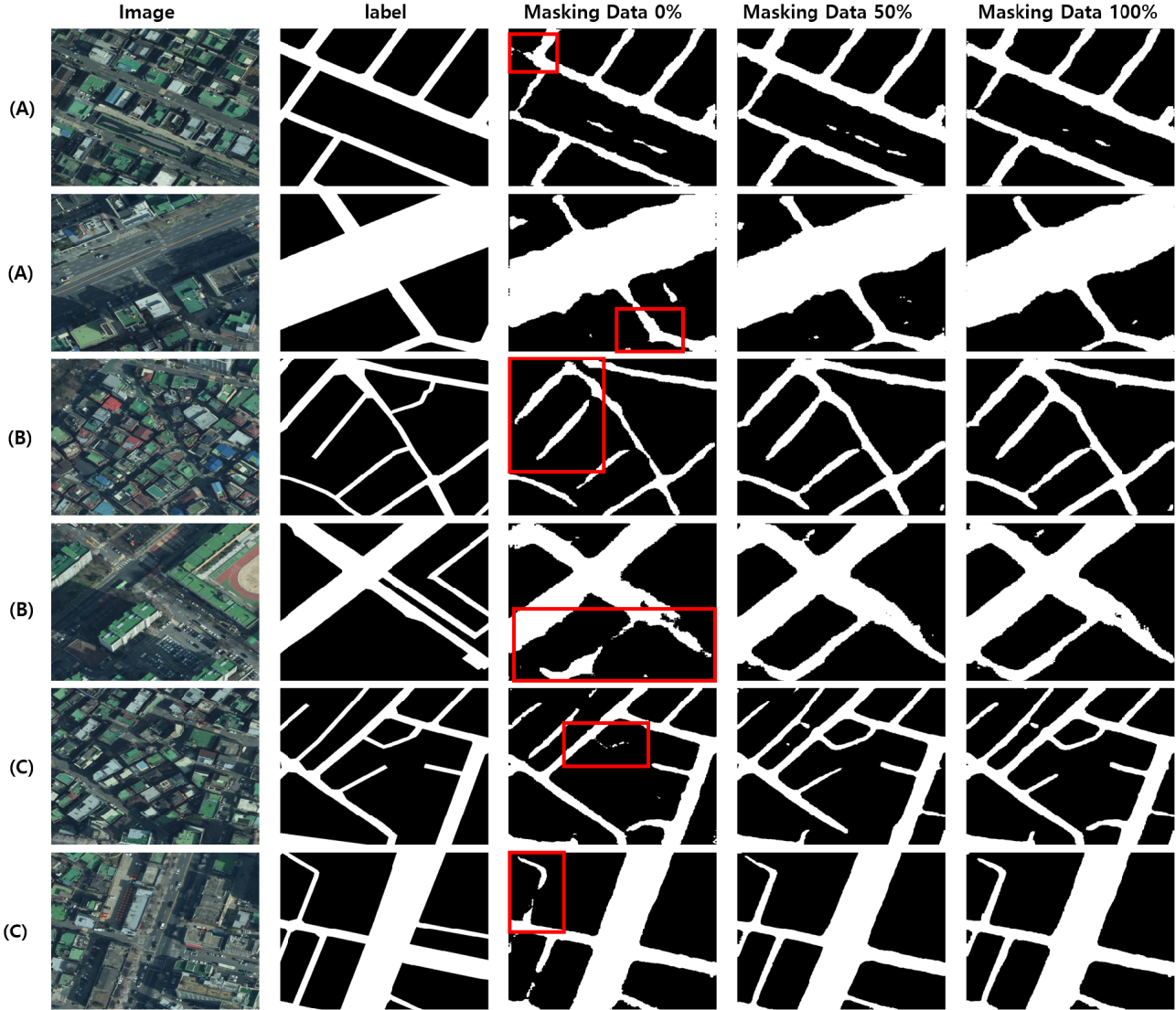
평가 지표를 활용한 인공 신경망 모형들의 성능 측정 결과는 표 2와 같다. 전체적으로 마스킹 데이터와 원본 데이터를 함께 사용한 경우 성능이 향상되었다. 마스킹 데이터와 원본 데이터를 혼합한 데이터셋(Masking Data 50%)으로 학습한 SegFomer의 성능이 가장 우수하였다. 원본 데이터로만 학습한 경우(Masking Data 0%)에 비해 mIoU값은 2.36%, APLS와 SSIM은 각각 1.17%, 1.67% 향상되었다. U-Net의 측정 결과에서는 mIoU 값은 1.47%, APLS의 값은 1.19%, SSIM의 경우 0.73%가 높아진 것으로 확인되었다. U-Net 역시 마스킹 데이터를 사용한 경우 성능 향상이 있었으나, SegFormer에 비해 상대적으로 낮은 향상률을 보였다. 또한 SegNet은 각각 0.56%, 0.99%, 0.46%로 다른 모델들에 비해서는 소폭 향상되었다. SegNet은 다른 모델들에 비해 마스킹 데이터의 영향을 상대적으로 적게 받은 것으로 확인된다.
표 2.
성능 평가표
마스킹 데이터만(Masking Data 100%) 적용한 결과에서 전반적으로 정밀도는 향상되고 재현율은 낮아지는 경향을 보였는데, 이는 마스킹 데이터가 도로의 주요 영역을 강조하는 효과를 가져왔음을 시사한다. 이러한 변화는 모델이 잘못 예측할 가능성이 있는 배경 영역을 제외하고 도로 영역에 더 집중하도록 유도했기 때문으로 해석할 수 있다.
4. 결론 및 시사점
본 연구에서는 원격탐사 영상으로 도로를 추출하는 과정에서 발생하는 도로 형태 왜곡 및 단절 문제를 해결하고자 하였다. 이를 위해 기존의 무작위 위치에 마스킹 영역을 삽입하는 데이터 증강 방식을 개선하여 도로 가장자리를 따라 무작위 추출 방법을 적용한 데이터 증강 방식을 제안하였다. 인공 구조물이나 나무 등의 객체로 인한 도로 왜곡 문제는 정확도를 저하시킬 수 있는 중요한 도전 과제이며, 기존 방식에서는 가림현상을 고려할 수 있는 데이터를 훈련에 충분히 사용하지 않아, 도로 영역과 배경 영역의 주요 특징을 반영하지 못하는 문제가 있었다. 따라서 본 연구에서는 도로의 경계에 해당하는 부분에만 무작위 위치에 무작위 크기의 마스킹 영역을 넣어 훈련 데이터를 제작하였다. 이를 통해 도로 경계 및 주요 특징을 강조하여 도로의 형태, 연결성과 같은 구조적 특징을 모델이 학습할 수 있도록 하였다. 분할 결과에 대해 기존의 픽셀기반 평가 지표와 함께 도로의 구조적 특성을 반영할 수 있는 APLS와 SSIM을 사용하여 도로의 형태와 연결성을 측정하였다.
마스킹 데이터의 효과 측정 및 최적 모형 선정을 위해 활용한 인공 신경망 모형은 U-Net, SegNet, SegFormer를 사용하였다. 먼저 가장 성능이 우수한 모형은 SegFormer이며 모든 평가 지표에서 비교 모형들에 비해 뛰어난 성능을 보였다. 마스킹 데이터의 적용 효과로는 마스킹 데이터를 적용한 경우, 원본 데이터만을 사용한 경우에 비해 도로의 의미론적 분할 정확도가 모든 측정 지표에서 향상되었으며, 도로의 연결성이 개선되었다. 또한 도로의 구조적인 특성을 평가하기 위한 APLS와 SSIM 지표에서도 성능이 개선되어 마스킹 데이터가 도로 추출 결과의 연결성에 미치는 긍정적인 영향을 입증하였다. 마스킹 데이터를 적용한 효과는 세 가지 모델 모두에서 확인되었으며, 의미론적 분할 성능 개선은 SegFormer, U-Net, SegNet 순으로 우수하였으며, 이러한 차이는 모델의 구조적 특성에 따라 마스킹 데이터의 효과가 다르게 나타날 수 있음을 시사한다.
본 연구는 도로 추출 성능을 향상시키기 위한 새로운 마스킹 데이터 적용 방식을 제안하였다. 기존의 무작위 위치에 마스킹 영역을 삽입하는 방식의 한계를 극복하고, 도로 경계에만 마스킹 영역을 삽입함으로써 도로의 형태와 연결성 학습을 강화하였다. 이를 통해 도로 추출 성능의 개선을 확인하였다. 이러한 결과는 마스킹 데이터를 효과적으로 활용하는 방법을 제시하며, 향후 원격탐사 영상 기반 도로 추출 연구에서 중요하게 기여할 수 있을 것이다.
