

1. 서론
2. 연구 범위 및 방법
1) 연구 범위
2) Long-Short Term Memory
3) 모형 입력 데이터 수집
3. 미세먼지 결측치 내삽 모형의 선정 및 정확도 검증
1) 모형 성능 평가를 위한 정확도 비교 방법
2) 입력 자료 조합 별 신경망 모형 성능 검토
4. 연구 결과
1) 동대문구 측정소 농도 결측 내삽 결과
2) 임의 결측 사례 지점의 지도화
3) 내삽 방식 적용 대상의 확장
5. 결론 및 시사점
1. 서론
미세먼지(Particulate Matter, PM)는 1990년대 주목을 받은 이래로 현재까지 대한민국의 자연 및 인문 환경에 악영향을 미치고 있다(오종민 등, 2017). 대기 중의 미세먼지는 인간의 건강에 있어서는 호흡기 질병의 악화, 폐 기능 저하 등을 일으키고, 생활 환경에 있어서는 식물의 신진대사 방해, 건축물의 부식 등의 문제를 야기한다. 한국환경공단에서 제공하는 대기환경기준물질 측정자료는 전국에 분포하는 대기측정망에서 수집된 1시간 단위의 미세먼지(PM10) 농도 자료를 포함한다(에어코리아, 2023). 이 자료는 한국의 고농도 미세먼지 문제의 해결을 위해 진행된 다수의 양적 연구에서 활용되고 있다(김성돈 등, 2021; 손상훈 등, 2020; 송인상 등, 2018; 이수민 등, 2021; 조경우 등, 2020; 최한수 등, 2020).
미세먼지는 시간 의존성과 공간 의존성의 특성을 모두 확인할 수 있는 현상으로, 미세먼지의 시간 의존성을 고려하는 연구는 주로 미래의 미세먼지 농도를 예측하는 것을 목적으로 한다(손건태・김다홍, 2015; 유숙현, 2019; 임동진 등, 2017; 조경우 등, 2020; Chaloulakou et al., 2003; Díaz-Robles et al., 2008; Mckendry, 2002; Ul-Saufie et al., 2011; Zhang, 2003). 특히 2000년대 이후 사람의 뇌 구조를 모방하여 학습을 통해 결과를 추정하는 인공 신경망(Artificial Neural Network, ANN) 기술을 활용한 미세먼지 농도 예측 모형은 과거 전통적으로 활용되어온 선형 회귀식이나 시계열 분석 모형에 비해 더 높은 정확도를 보이고 있다(Ul-Saufie et al., 2011). 고정된 측정소에서 매시간 측정되는 미세먼지 농도 자료는 시계열 자료이기 때문에, 미세먼지 농도를 순환 신경망 모형의 입력 자료로 활용하는 연구가 다수 진행되었으며(임동진 등, 2017; 최한수 등, 2020), Multiple Layer Perceptron(MLP)에 비해 더 나은 예측 정확도를 보여 왔다(임동진 등, 2017). 미지의 값에 대한 추정을 기반으로 한다는 점에서, 최근의 미세먼지 예측 연구에서 높은 정확도를 보이는 대표적인 순환 신경망 모형인 LSTM 모형을 결측치의 내삽을 위한 도구로 고려해 볼 수 있을 것이라 판단할 수 있다. 한편, 공간 의존성을 고려하는 미세먼지 연구는 미세먼지 농도 측정소의 위치에 관련하여 이루어져 왔다. 특히 공간적 측면에서의 대부분의 미세먼지 연구는 IDW(Inverse Distance weighting), 크리깅(Kriging)으로 대표되는 공간 내삽 기법을 주로 활용하였다(김성돈 등, 2021; 김효정・조완근, 2012; 박노욱, 2011; 송인상 등, 2018; 정예민 등, 2021; 조홍래・정종철, 2009; Chae et al., 2021; Jha et al., 2011).
시계열 자료에서 결측치는 연속적인 시간 흐름을 고려하는 과정에서 방해가 되는 요소이며, 1시간 단위로 측정되는 시계열 자료인 미세먼지 농도 자료의 결측치는 해당 자료를 활용한 시계열 분석 결과를 왜곡할 가능성이 있다(송인상 등, 2018). 정확한 결측치 대체를 통해 제공될 수 있는 양질의 관측농도자료는 국내 미세먼지 농도에 대한 분석의 정확도 향상을 위해 필수적이다. 기존의 연구에서는 미세먼지 농도 자료를 분석에 활용할 때, 자료에 포함된 결측치를 주로 평균이나 선형 내삽과 같은 단순한 방법으로 해결했다(조경우 등, 2020; Abdullah et al., 2017; Kristiani et al., 2022; Seng et al., 2021). 그러나 자료의 결측치를 추정할 때, 기존 연구와 같이 시간 또는 공간적 특성의 한 가지만 고려하는 추정 방식은 분석 결과의 정확도에 부정적인 영향을 미칠 수 있다.
따라서 본 연구는 미세먼지 농도 자료에 결측이 발생했을 때, 시공간적 특성을 모두 고려하여 결측을 내삽하는 방법을 제안하고자 하였다. 시계열 자료의 시간 의존성을 고려하기 위해 최근 미세먼지 농도 추정에 있어 높은 정확도를 보이는 신경망 모형인 LSTM(Long Short Term Memory) 모형을 활용하였다. 다음으로, 측정망 주변의 공간적 특성을 고려하기 위해 주변 ASOS에서 제공하는 기상 정보, 주변 측정소의 미세먼지 농도와 측정소 간 공간적 자기상관을 확인할 수 있는 지수()를 수집 및 계산하여 신경망 모형의 입력자료로 활용하였다. 또한 시공간 특성을 고려한 신경망 모형의 성능을 확인하기 위해 전통적인 공간 내삽 기법의 결과와 비교하였다. 본 연구에서 제안된 결측치 내삽 모형을 활용하여 가공된 미세먼지 농도 자료를 사용한다면 다양한 미세먼지 분석 결과의 정확도 향상에 기여할 수 있을 것으로 기대한다.
2. 연구 범위 및 방법
1) 연구 범위
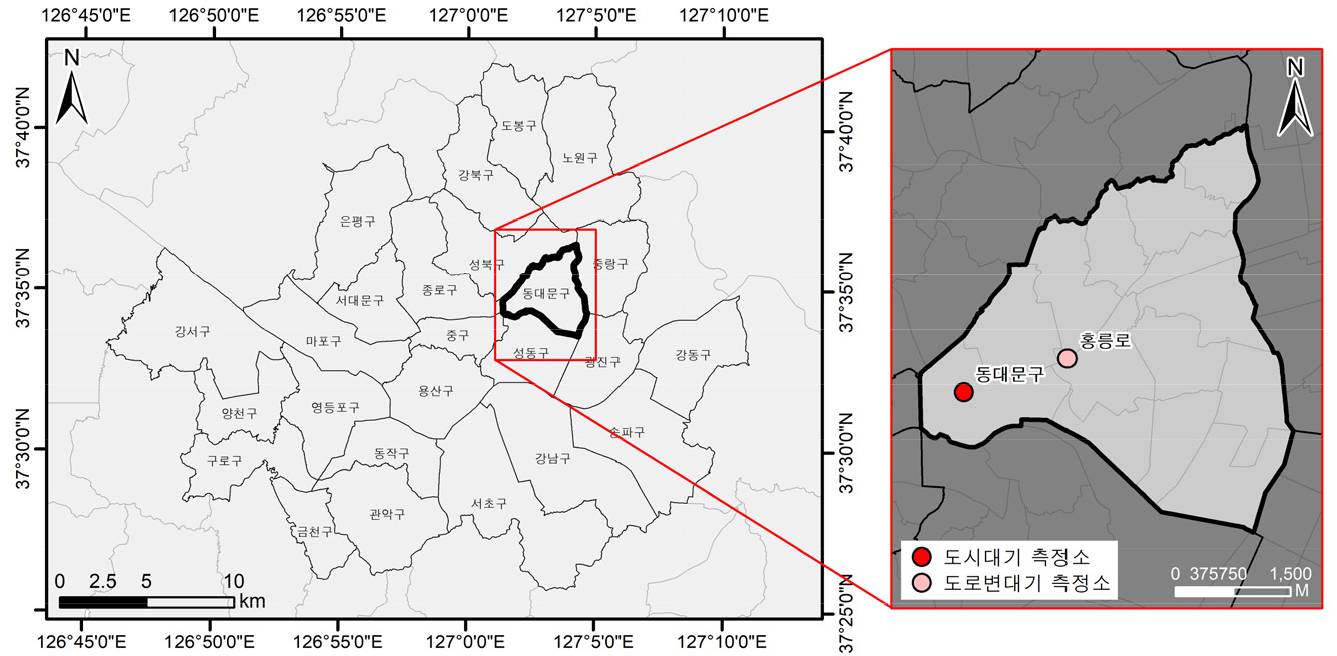
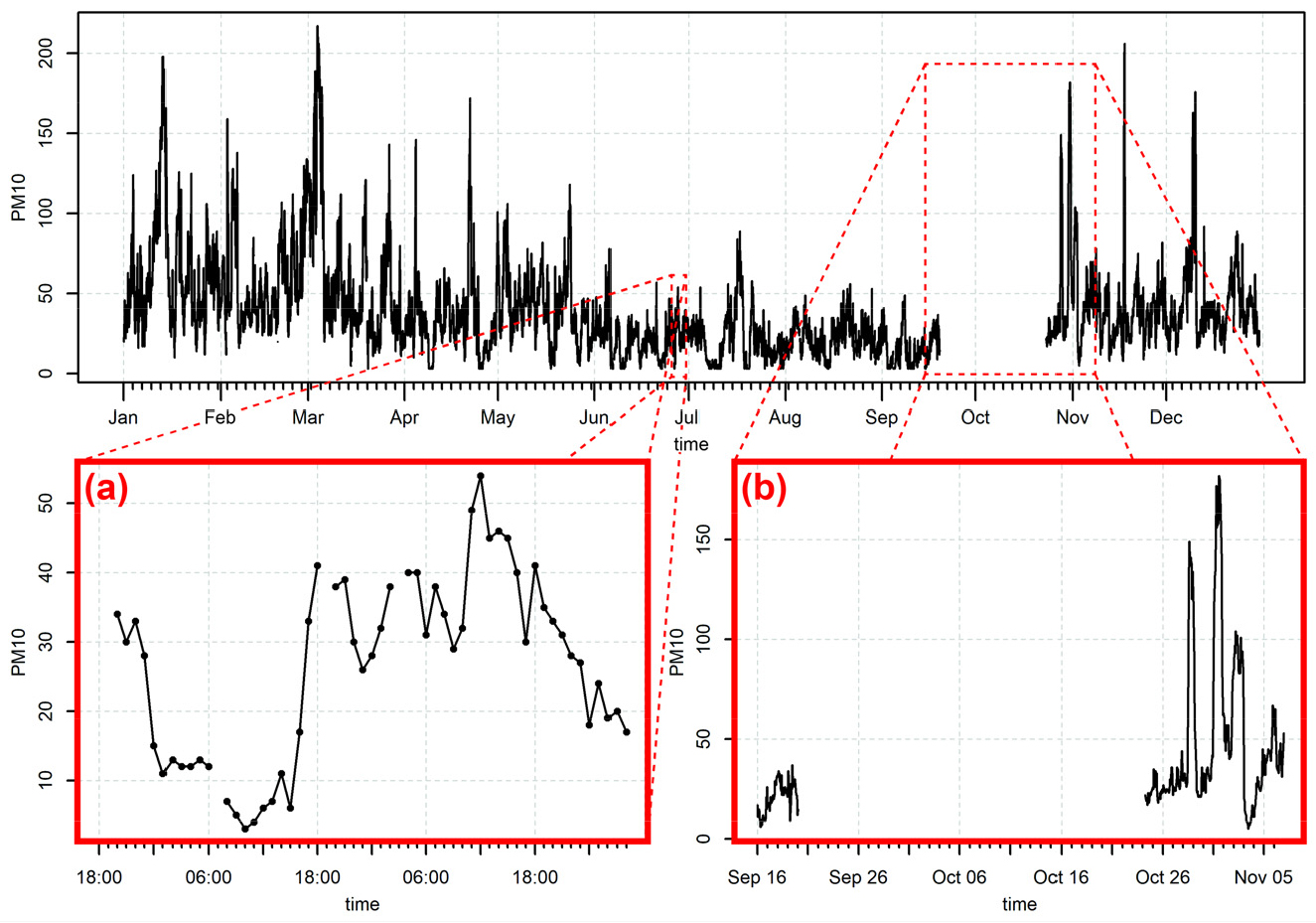
본 연구에서의 결측치 내삽 대상 측정소는 대한민국 서울특별시 동대문구에 위치한 대기질 측정소 중 도시대기측정망 측정소에 해당하는 동대문구 측정소이다. 동대문구 측정소를 대상 측정소로 선정한 이유는 내삽 대상 시점인 2019년 동대문구 측정소 농도가 선행 연구의 신경망 모형을 활용한 결측 대체 문제에서 고려되는 결측의 형태인 장기 결측과 단기 결측을 모두 가지고 있기 때문이다. 그림 1은 동대문구 측정소 위치지도이고, 그림 2는 본 연구에서 결측의 내삽을 진행할 검증 대상 연도인 2019년의 동대문구 측정소 측정 미세먼지 농도 그래프이다. 그림 2(a) 시점은 2019년 6월 26일 오후 6시부터 2019년 6월 29일 오전 4시 사이의 농도 측정 결과이다. 해당 시점에서는 산발적이고 일시적으로 결측이 발생하고 있다. 이러한 단기 결측의 형태는 결측 발생 시작 시점과 종료 시점 간 범위가 시점 1~2 정도로 좁은 것이 특징이다. 한편 그림 2(b) 시점은 2019년 9월 16일 오후 2시부터 2019년 11월 7일 오후 1시 사이의 농도 측정 결과이다. (a) 시점과는 대조적으로, (b) 시점에서는 상대적으로 결측 발생이 약 1개월간 지속되고 있는 장기 결측의 형태를 보이고 있다.
2) Long-Short Term Memory
신경망(Neural Network)은 경험을 통해 학습을 진행하는 사람의 뇌 구조를 모방한 모형으로, 입력층, 출력층과 그 사이를 연결하는 은닉층으로 구분된다. 순환 신경망(Recurrent Neural Network, RNN)은 은닉층이 이전 데이터를 참조하도록 연속적인 시간상에서 연결되어있는 형태이다(Géron et al., 2019). 순환 신경망은 신경망의 은닉층을 거쳐 도출된 출력이 다음번의 입력층의 입력과 함께 은닉층의 입력으로 돌아가는 재귀 구조를 갖는다. 그러나 RNN은 단기 기억에 비해 장기 기억을 유지하지 못하는 장기 의존성 문제(Long-term Dependency)를 가진다(고관섭 등, 2021).
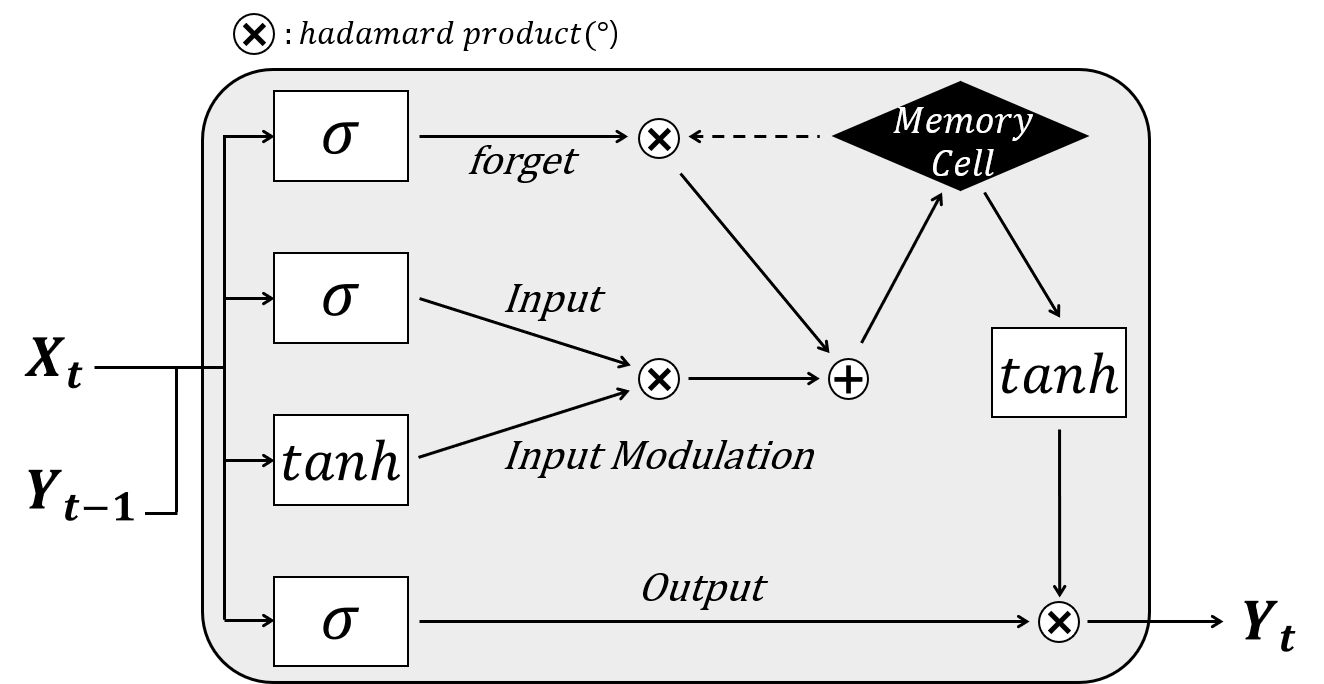
LSTM(Long Short Term Memory)은 장기 의존성 문제를 해결하기 위해 과거 시점의 데이터들을 저장해두는 기억 셀을 포함한 모형이다(Hochreiter and Schmidhuber, 1997). 그림 3은 LSTM 모형의 내부 모식도이고, <식 1>에서 <식 4>는 LSTM 모형의 순전파 계산 과정으로, 현시점의 데이터인 와 이전 시점 출력값인 를 통해 현시점의 출력값인 를 도출한다.
여기서, 와 는 출력 의 계산을 위해 사용되는 게이트별 결과물이고, 와 는 각각 입력 와 출력 에 상응하는 가중치, 는 편향, 는 기억 셀을 의미한다. 는 현시점을 의미하고, -1는 직전 시점(이전 시점)을 의미한다. tanh와 𝜎는 활성화 함수로, 각각 하이퍼볼릭 탄젠트 함수, 시그모이드 함수를 의미한다. LSTM은 크게 4개의 게이트로 구분되어 있다. 이를 각각 망각(forget), 입력(Input), 새로운 기억(Input Modulation), 출력(Output)이라고 부른다(Hochreiter and Schmidhuber, 1997).모든 게이트에 대해, 가중치와 편차, 활성화 함수가 적용되는 과정은 동일하다. 현시점의 입력 데이터 와 이에 상응하는 가중치 행렬 , 이전 시점의 출력 와 이에 상응하는 가중치 , 그리고 를 통해 계산된 값 에 각각의 활성화 함수를 적용하여 를 도출한다. 를 바탕으로 를 도출한 후 와 를 결합하여 를 추정한다.
3) 모형 입력 데이터 수집
미세먼지 농도는 연속면에서 점진적으로 변하는 특성이 있으므로, 이웃 측정소의 농도값과 더 유사한 공간적 특성을 갖게 된다. 따라서 시간적 특성을 반영하는 LSTM 모형에 공간적 특성을 고려한 입력 데이터를 활용하면 내삽 결과의 향상을 기대할 수 있을 것이다. 이를 위해 다음과 같이 LSTM의 입력 데이터를 가공하였다. 본 연구에서는 대상 측정소의 공간적 관계를 고려하는 신경망 모형의 입력 데이터를 구성하기 위해 세가지 데이터를 제작하여 활용하였다. 첫번째 데이터는 내삽을 진행할 대상 측정소와 가장 가까운 거리의 종관기상관측장비(Automated Synoptic Observing System, ASOS)에서 수집된 기상 정보이다. 기상 정보는 기존의 미세먼지 농도 예측 연구에서 가장 빈번하게 활용되는 자료로, 본 연구에서는 선행연구를 통해 주로 활용되는 6가지 항목(기온, 강수량, 풍속, 풍향, 습도, 해면기압)을 선정하여 입력 데이터로 활용하였다(조경우 등, 2019; 차진욱・김장영, 2018; Abdullah et al., 2017; Chaloulakou et al., 2003; Dedovic et al., 2016; Pires et al., 2008). 두번째 데이터는 대상 측정소와 상대적으로 가까운 거리의 대기질 측정소에서 측정된 농도 정보이다. 이때 대상 측정소 내삽 모형의 입력 데이터로 활용되는 대기질 측정소를 ‘이웃 측정소’, ASOS를 ‘이웃 ASOS’라고 명명하였다. 세번째 데이터는 대상 측정소를 기준으로, 이웃 측정소 범위보다 상대적으로 먼 거리의 정보를 수집하였으며, 대상 측정소와 주변 측정소의 미세먼지 농도 자료를 활용하여 공간적 군집을 확인할 수 있는 지수인 Getis-Ord 를 계산한 결과를 모형의 입력 데이터로 활용하였다.
첫번째, 두번째 데이터의 수집을 위해 활용한 이웃 측정소 및 이웃 ASOS 선정 과정은 크게 5가지 단계로 구분된다. 먼저 결측의 내삽을 진행하려는 측정소(이하 내삽 대상 측정소)와 가장 근거리에 위치해 있는 ASOS를 선택하여, 해당 지점에서의 자료를 본 연구의 입력 기상 자료로 활용하였다. 다음으로 내삽 대상 측정소가 포함된 시군구 단위의 행정구역 경계를 검색한다. 이후 검색된 행정구역을 기준으로 경계를 공유하는 주변 행정구역을 검색한다. 이렇게 검색된 주변 행정구역에 포함되는 모든 대기질 측정소를 추출한 뒤, 본 연구의 시간적 범위인 2015년부터 2019년 사이에 해당 측정소에서 측정된 1시간 단위 미세먼지 농도 자료의 결측 비율을 계산한다. 결측 비율이 50% 이상인 측정소는 내삽의 정확도를 위해 사용 대상 이웃 측정소 목록에서 제외한다. 이러한 과정을 거쳐 선택된 ASOS와 주변 대기질 측정소를 내삽 대상 측정소의 이웃 ASOS와 이웃 측정소로 활용한다.
세번째 데이터 수집을 위해 국지적인 공간 군집의 위치를 확인할 수 있어, 신경망 모형의 입력 데이터로 이웃 측정소와 내삽 대상 측정소 간의 공간적 관계를 각 측정소별로 계산할 수 있는 Getis-Ord 지수를 활용하였다(Mitchell, 2005). <식 5>는 Getis-Ord 의 계산식이다.
여기서 는 사상의 속성값이고, 는 사상 와 사이, 즉 이웃으로 설정한 사상들 간의 가중치, 은 전체 사상의 개수이다. Getis-Ord 값이 양수일 경우 해당 사상은 높은 값을 갖는 사상이 군집해있는 지역에 위치하고 있음을 의미하고, 음수일 경우 낮은 값을 갖는 사상이 군집해있는 지역에 위치하고 있음을 의미한다. 이때 높은 값이 군집해있는 지역, 즉 가 양수인 지역을 Hot spot, 낮은 값이 군집해있는 지역, 즉 가 음수인 지역을 Cold spot이라고 하기 때문에, Getis-Ord 계산 분석을 Hot Spot 분석이라고 부르기도 한다(장문현, 2016).
본 연구에서는 Getis Ord 계산을 위해 점형 사상인 주변 측정소와 내삽 대상 측정소를 면형 사상화하였으며, 면형 사상 내 모든 위치가 다른 면형 사상의 입력 점 사상보다 해당 면 사상의 입력 점 사상에 가장 가깝도록 면형 사상을 제작하는 Thiessen Polygon 제작 알고리즘을 활용하였다(Brassel and Reif, 1979). 또한 는 그 값이 표준정규분포를 따른다는 가정으로 계산되기 때문에, 계산에 활용될 표본의 수를 최소 30개 이상으로 선정해야 할 필요가 있다. 따라서 내삽을 진행할 측정소 위치를 기준으로 31개의 최근접 이웃에 해당하는 대기질 측정소를 추출한 후 계산에 활용하였다. 마지막으로 계산의 공간 가중치 설정은 앞서 이웃 대기질 측정소를 선정하는 방법과 동일하게 Queen 인접성 방식(경계를 공유하는 모든 시군구 단위 행정구역 대상)을 기반으로 하였다.
3. 미세먼지 결측치 내삽 모형의 선정 및 정확도 검증
본 연구에서는 결측치 내삽 및 검증 과정을 크게 세 단계로 나누어 진행하였다. 먼저 데이터 조합에 따른 모형의 정확도 비교를 통해 최종적인 신경망 모형을 선정하였다. 수집 과정에서 공간 관계를 고려하고 있는 자료들을 신경망 모형의 입력 데이터로 사용했을 때, 모형 예측 결과에 어떠한 영향을 미치고 있는지 그 여부를 판단하고자 하였다. 다음으로, 선정된 모형을 사용한 결측치 내삽의 결과 정확도를 검증하기 위해 타 공간 내삽 방법의 결과와 비교하였다. 마지막으로, 연구에서 제안한 신경망 모형의 범용성을 확인하기 위해 서울시내 10개 대기질 측정소에 대해 동일한 과정을 적용하여 각 측정소별 결측치 내삽 모형을 학습하였다. 이후 임의의 결측 지점에 대해 선형 내삽, IDW, 정규 크리깅과 연구에서 활용한 신경망 모형을 포함하여 총 4가지 방법의 농도 내삽 결과의 정확도를 비교하였다.
1) 모형 성능 평가를 위한 정확도 비교 방법
신경망 모형 제작을 위해 입력 자료를 척도화한 후 조합별 모형 적합 결과를 비교함으로써 최적의 내삽 신경망 모형을 도출하였다. 선정된 모형으로 대기측정소의 내삽을 진행하였다. 모델의 성능 비교를 위해 임의의 결측 지점에 대해 결정론적 내삽 방법인 선형 내삽, 역거리 가중치 내삽 방법과 추론 통계학을 기반으로 하는 지구 통계학의 일종인 크리깅 방식 중 정규 크리깅방법을 적용한 후 그 결과를 비교하였다(Lepot et al., 2017). 정확도 비교를 위해 활용한 성능 평가 지표는 Root Mean Squared Error(RMSE), Mean Absolute Error(MAE), Root Mean Squared Log Error(RMSLE)이며, 이중 RMSE에 로그를 씌워 계산한 RMSLE는 과대 추정과 과소 추정의 오류 중 과소 추정의 오류에 더 큰 페널티를 부여한다는 것이 특징이다(Kim et al., 2022; McHugh et al., 2021; Muhlestein et al., 2019). 미세먼지 농도 자료의 경우 현재 대기 현황을 파악하여 이를 기반으로 예・경보를 발령하는 데에 활용되기 때문에, 실제값보다 낮은 값으로 내삽이 이루어질 때 상대적으로 더 민감하다.
2) 입력 자료 조합 별 신경망 모형 성능 검토
기상 자료의 경우 내삽 대상 측정소의 이웃 ASOS 자료를 대상으로 하였다. 대상 측정소인 동대문구 측정소와 가장 가까운 거리에 있는 ASOS는 서울(지점번호: 108, 서울특별시 종로구 송월길 52) 관측소로 확인되었고, 이 관측소를 이웃 ASOS로 선정한 후, 6개 관측 자료(기온, 강수량, 풍속, 풍향, 습도, 해면기압)를 추출하였다.
PM10 농도 자료의 경우 내삽 대상 측정소의 이웃 측정소에서 관측된 자료를 대상으로 하였다. 대상 측정소인 동대문구 측정소의 경우 시군구 단위 행정구역인 ‘동대문구’를 기준으로 총 6개의 행정구역이 경계를 공유하고 있었다(광진구, 성동구, 성북구, 종로구, 중구, 중랑구). 해당 행정구역 내에 포함되는 측정소는 총 11개로, 도시대기 측정소인 중구, 종로구, 광진구, 성동구, 중랑구, 성북구 6개 측정소와 도로변 대기 측정소인 청계천로, 종로, 강변북로, 홍릉로, 정릉로 5개 측정소가 이웃 측정소로 선정되었다. 11개 측정소 모두 2015년부터 2019년 사이 결측치가 전체 관측의 50% 미만임을 확인하였다.
두 개 이상 유형의 데이터를 입력 데이터로 활용하는 모형의 경우 발생하는 데이터의 척도 문제를 해결하기 위해 각 데이터의 값의 범위를 0에서 1 사이로 변환하였다. 조합된 데이터는 sliding window 기법을 통해 24시간 동안의 데이터 묶음(입력)과 바로 다음 시간대에 동대문구 측정소에서 측정된 PM10 농도인 해당 묶음의 정답(출력, 라벨) 형태의 샘플로 변환하였으며, 훈련 데이터셋(Train dataset)의 경우 결측치였던 정답을 포함하는 샘플은 제거하였다. 모형의 훈련 데이터셋은 2015년 1월 1일 오전 1시부터 2019년 1월 1일 오전 0시까지의 자료를 사용하였고, 검증 데이터셋(Test dataset)은 2019년 1월 1일 오전 1시부터 2020년 1월 1일 오전 0시까지의 데이터를 사용하였다. 표 1은 세 가지 경우의 입력 데이터 조합별 모형 형태 및 명칭을 보여준다.
표 1.
입력 데이터 조합별 모형 명칭 및 형태
표 1의 입력 데이터 조합을 적용하기 위해 본 연구에서 제작한 신경망 모형은 총 4개의 층으로 이루어져 있으며, 첫 번째부터 세 번째 층은 LSTM 층, 마지막 층은 출력층으로 제작하였다. LSTM 층의 뉴런 개수는 순서대로 64, 32, 16으로 설정하였다. 제작한 모형의 활성화 함수는 LSTM 모형의 활성화 함수 기본값인 하이퍼볼릭 탄젠트로, 학습률은 0.001로 설정하였고, 최적화 함수는 Adam을 활용하였다. 1회 학습 진행 시 사용될 sample의 개수를 의미하는 batch와 전체 데이터셋이 학습을 완료하는 횟수를 의미하는 epoch, 과적합을 방지하기 위해 설정하는 dropout 비율의 경우 gridsearch를 기반으로 수행하는 교차 검증의 방법 중 하나인 k-fold 교차 검증을 활용하여 그 값을 결정하였다. 이웃 ASOS자료, 이웃 측정소 농도 자료, 자료를 모두 입력 데이터로 사용하는 경우의 모형을 대상으로 교차 검증을 진행하였고, k의 개수는 3으로 설정하였으며, 이에 따라 총 34,367개의 훈련 데이터셋을 22,911개의 훈련 데이터셋과 11,456개의 검증 데이터셋으로 구분하였다. 하이퍼파라미터의 경우 batch size는 32, 64, 128, 256을 선택하였고, epochs는 10부터 50까지 10단위로 선택하였다. dropout rate는 0.0부터 0.4까지 0.1 단위로 선택하였다. 교차 검증 과정을 통해 선정한 최종 모형의 구성은 표 2와 같다.
표 2.
최종 선정 모형 구성
동대문구 측정소에 대해 입력 데이터 조합별 모형 예측 정확도를 비교한 결과는 그림 4와 같다. 이때 모형의 정확도를 비교하기 위해 검증 데이터셋(Test dataset)을 Validation data로 설정하여, epoch 진행에 따른 훈련 및 검증 데이터셋의 손실 함숫값의 변화를 확인하였다. 그림 4의 왼쪽 그래프는 훈련 데이터의 epoch 진행에 따른 손실 함수 MAE의 변화를 보여주며, 오른쪽 그래프는 검증 데이터의 epoch 진행에 따른 변화를 보여준다.
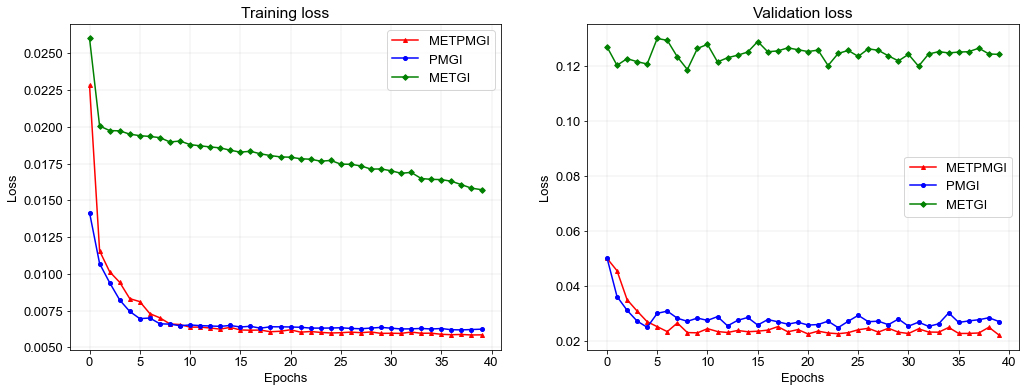
그림 4를 통해 훈련 데이터셋의 경우 모든 모형이 학습이 진행될수록 손실이 낮아지고 있지만, 기상 자료만 활용한 모형(METGI)은 검증 데이터셋의 손실이 낮은 값으로 수렴하지 못하는 그래프를 보이고 있었다. 이웃 측정소 농도 자료를 활용한 모형(PMGI)과 모든 자료를 활용한 모형(METPMGI)은 훈련 데이터셋과 검증 데이터셋 모두 낮은 값으로 수렴하며, 특히 모든 자료를 활용한 모형의 최종 손실률이 상대적으로 더 낮게 계산되는 것을 확인할 수 있었다. 이를 통해 최종적인 모형은 모든 자료를 활용한 모형으로 선정하였다.
4. 연구 결과
1) 동대문구 측정소 농도 결측 내삽 결과
선정된 모형을 통해 수행한 내삽 결과의 정확도를 검토하기 위해 대상 측정소에 임의의 결측치를 생성한 후 본 연구에서 제작한 모형을 포함한 다양한 내삽방법을 사용하여 결측치 내삽을 진행하였다. 그림 5는 방법별 내삽 결과를 표현한 그래프이며, 각각의 그래프 하단에는 임의 결측치 위치마다 해당 시점의 실제 관측치와 추정치의 차이의 크기에 따라 색의 투명도를 조절해 표현한 잔차 그래프를 포함하였다. 모든 잔차 그래프의 색 범위는 동일하게 설정하였으며, 붉은색이 진할수록 해당 시점의 잔차가 크다는 것을 의미한다. 그림 5(a)는 선형 내삽방법을 통해 결측치를 내삽한 결과, 그림 5(b)는 IDW 방법을 활용하여 결측치를 내삽한 결과이다. 그림 5(c)는 정규 크리깅을 활용하여 결측치를 내삽한 결과이고, 그림 5(d)는 LSTM을 활용하여 연구에서 제작한 신경망 모형으로 결측치를 내삽한 결과를 보여준다.
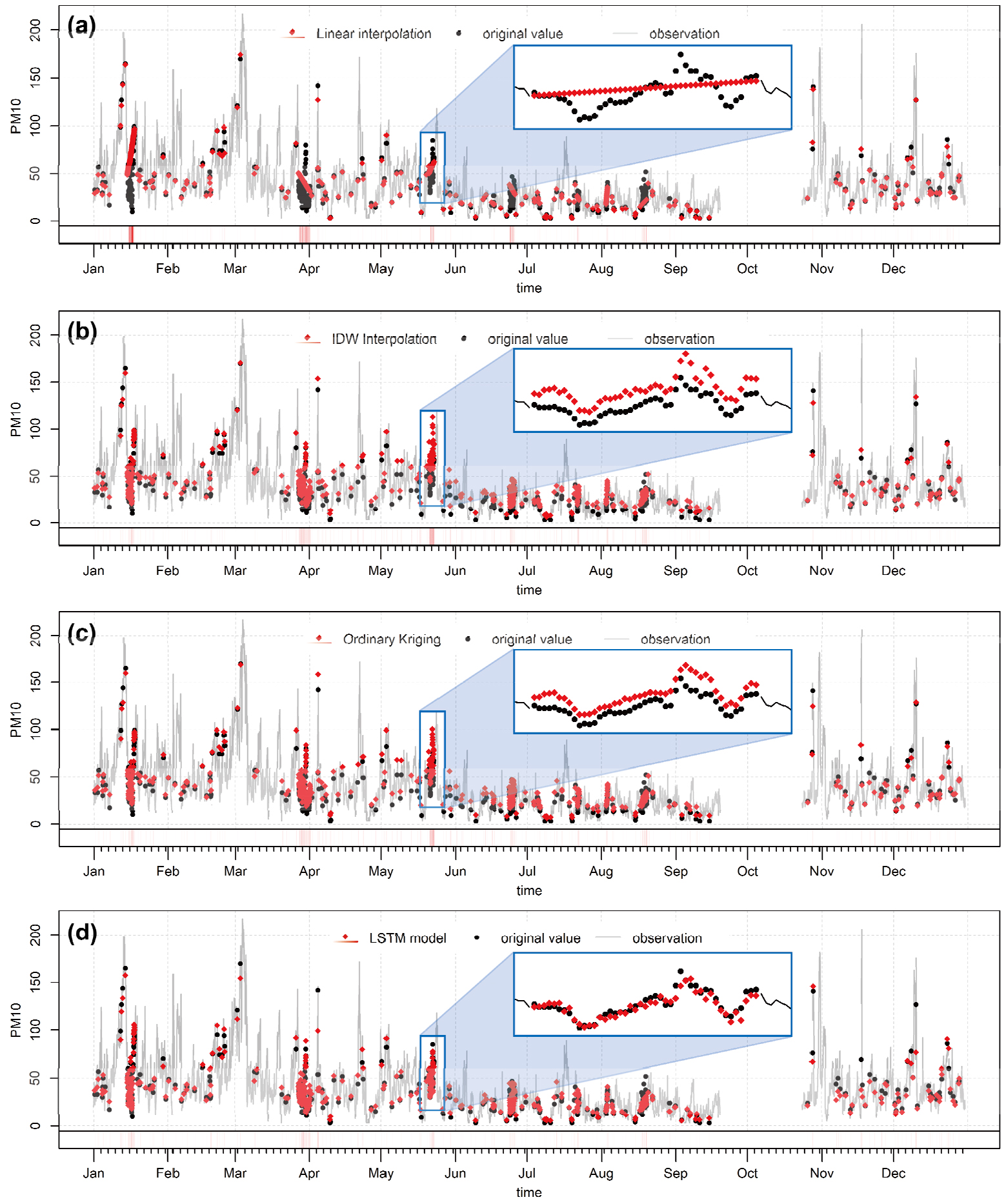
그림 5를 통해 내삽의 과정에 소요되는 통계적, 혹은 비(非)통계적 계산이 복잡해질수록 그 결과의 정확도가 높아짐을 확인할 수 있었다. 잔차 그래프는 그림 5(d) 그래프인 신경망 모형의 결과가 전반적으로 가장 연한 붉은 색을 띠고 있으며, 이는 신경망 모형의 내삽 결과 추정값과 실제 관측치의 차이가 상대적으로 적다고 볼 수 있다. 한편 그림 5(a)의 선형 내삽은 데이터의 결측 해결에 주로 활용되는 방법이지만, 장기적으로 결측이 발생한 시점에 대해 다른 방법에 비해 매우 낮은 정확도를 보이고 있다. 선형 내삽은 결측 발생 직전 시점의 관측치와 직후 시점의 관측치 총 2개의 관측치만이 결측치 내삽 계산에 사용되기 때문에, 다른 방법들에 비해 상대적으로 낮은 정확도를 보일 수 있다고 추측해볼 수 있다. 공간내삽기법인 IDW와 정규 크리깅은 잔차 그래프를 통해서는 내삽 정확도의 차이를 파악하기 어렵다. 특히 그림 5의 그래프 내부의 확대 상자로 표현한 5월 22일 경에 생성된 결측은 장기 결측의 형태를 보이고 있음에도, 잔차 그래프를 통해 내삽에 활용되는 관측치가 2개뿐인 선형 내삽의 결과(그림 5(a))와 비교했을 때 이웃 측정소의 농도를 함께 고려할 수 있는 공간 내삽의 결과(그림 5(b), 그림 5(c))의 정확도도 높지 않음을 확인할 수 있었다. 이는 장기 결측 형태일 경우에도, 시간 의존성을 고려하지 않은 채 공간 의존성만을 고려하는 방법으로 진행된 결측치 내삽은 낮은 정확도를 가질 수 있음을 의미한다. 그러나 본 연구에서 사용한 LSTM 모형은 시간 의존성을 고려하는 한편 공간 관계를 포함하는 입력 데이터를 기반으로 학습되었기 때문에 그 내삽 결과(그림 5(d))가 공간 내삽 결과에 비해 해당 시점의 결측 내삽 정확도가 높음을 알 수 있다.
각 방법의 내삽 결과값을 바탕으로, 내삽 방법의 정확도를 수치로 비교하기 위해 3가지 성능 지표(MAE, RMSE, RMSLE)를 계산한 결과는 표 3과 같다. 성능 지표 중 RMSE를 기준으로 할 경우 신경망 모형 방법이 가장 높은 정확도를 보이고 있으며(5.84522), 다음으로 정규 크리깅(6.55451), IDW(7.18001), 선형 내삽(19.14626) 순으로 높은 정확도를 보이고 있었다. 전반적으로 신경망 모형 방법이 모든 성능 지표에 대해 가장 높은 내삽 정확도를 보이고 있었다.
표 3.
방법별 내삽 결과 정확도 비교 성능 지표 계산 결과
2) 임의 결측 사례 지점의 지도화
결측 발생 시점의 결측 측정소를 포함하는 지역에 대해 시간당 미세먼지 농도 분포 지도를 제작할 경우, 특히 지역이 국지적인 범위일수록 측정소의 결측 여부가 지도에 큰 영향을 미칠 수 있다. 따라서 임의로 제작한 결측 지점에 대해, 결측 내삽 방법별로 계산된 결과값을 활용하여 공간 내삽 기법을 활용한 농도 분포 지도를 제작하고, 각 방법별 지도 제작의 특성을 비교하였다.
농도 분포 지도는 IDW 방법을 활용하였고, 동대문구 측정소에서 결측이 발생한 상황을 가정한 후 앞서 선정된 12개의 동대문구 측정소의 이웃 측정소 농도 자료와, 4가지 내삽 방법별 결측 지점 추정값을 활용하여 분포 지도를 제작하였다. 임의의 결측 지점 중 단기 결측 형태를 보이는 2019년 1원 23일 18시를 사례로 분포 지도를 제작하였으며, 제작된 분포 지도는 그림 6에서 확인할 수 있다.
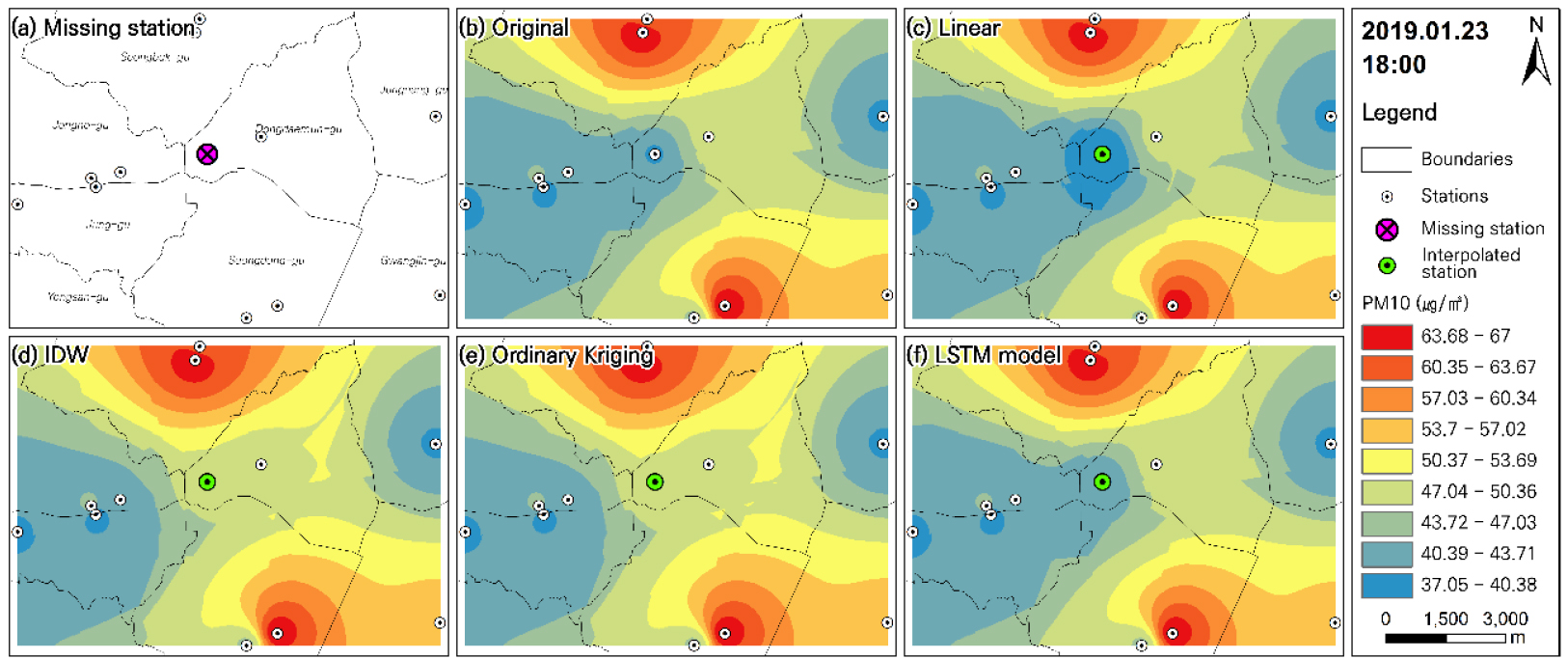
그림 6(a)은 결측이 발생한 지점을 포함하는 측정소 위치 지도이다. 그림 6(b)은 실제로 동대문구 측정소에서 관측된 농도를 이웃 측정소의 농도와 함께 분포 지도 제작에 사용한 결과이다. 그림 6(c)은 동대문구 측정소 지점에 대해, 선형 내삽 방법으로 추정한 농도를 분포 지도 제작에 사용한 결과지도이고, 그림 6(d)은 IDW 내삽 방법으로 추정한 농도를 분포 지도 제작에 사용한 결과지도이다. 그림 6(e)은 정규 크리깅 기법으로 동대문구 측정소의 농도를 추정한 후 그 결과를 지도 제작에 사용한 결과지도이고, 그림 6(f)은 본 연구에서 제시한 신경망 모형으로 동대문구 측정소의 농도 내삽을 진행한 결과를 사용하여 농도 분포 지도를 제작한 결과이다.
그림 6을 통해 실제 관측값으로 계산된 그림 6(b)과 가장 유사한 지도는 신경망 모형을 통한 내삽 결괏값이 포함된 그림 6(f)임을 확인하였다. 선형 내삽 결과를 포함하는 그림 6(c)은 2019년 1월 23일 18시의 경우, 이전 시점인 2019년 1월 23일 17시와 이후 시점인 2019년 1월 23일 19시의 관측값을 기반으로 내삽을 진행하는데, 실제 18시의 미세먼지 농도는 40㎍/㎥이었으며, 17시의 농도는 40㎍/㎥이고, 19시의 농도는 30㎍/㎥이었다. 따라서 선형 내삽은 40과 30의 평균값인 35로 결측 지점 값을 추정했기 때문에 실제 지도인 그림 6(b)에 비해 그림 6(c)의 결측 발생지점 주변 값이 더 낮게 추정되는 결과를 보이고 있다고 할 수 있다. 반면 이전 시점과 이후 시점의 관측값을 고려하지 않고, 주변 측정소와의 거리와 각 측정소별 농도만을 고려하는 IDW(그림 6(d)), 정규 크리깅(그림 6(e)) 결과는 그림 6(b)의 결측 발생지점 주변의 값 분포 보다 높게 계산되는 결과를 확인할 수 있었는데, 이는 동대문구 측정소 이외에 동대문구에 위치하는 가장 가까운 거리의 대기질 측정소인 홍릉로 측정소의 농도에 영향을 크게 받았을 것으로 판단된다.
3) 내삽 방식 적용 대상의 확장
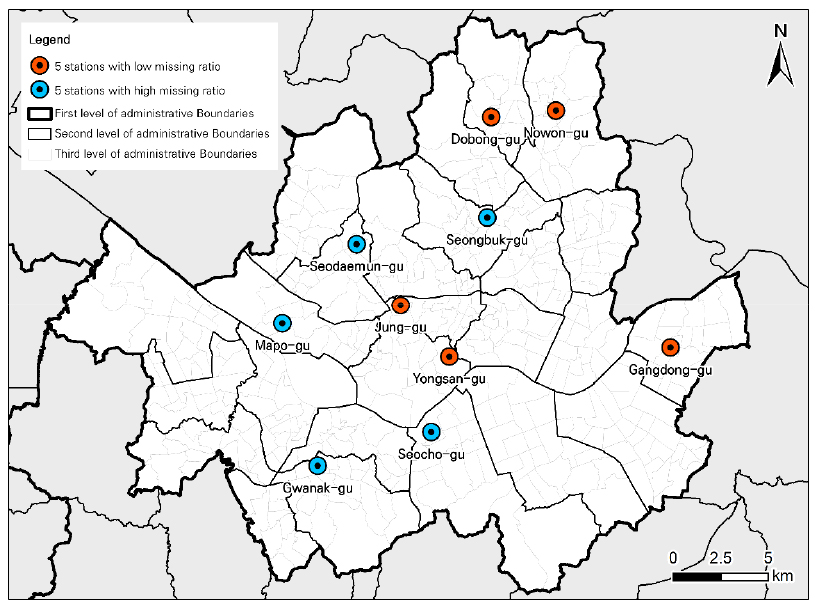
연구에서 제작한 모형의 적용 범위를 확장하기 위해, 동대문구 측정소 이외에, 10개 측정소를 추가 선정하였다. 10개 측정소는 서울시내에 존재하는 도시대기 측정소인 노원구, 중구, 강동구, 도봉구, 용산구, 관악구, 서초구, 성북구, 마포구, 서대문구 측정소이다. 이 측정소들은 2015년부터 2019년 사이에 발생했던 결측의 비율을 기준으로 선정하였으며, 가장 결측의 비율이 낮았던 상위 5개 측정소(노원구, 중구, 강동구, 도봉구, 용산구 측정소)와 가장 결측의 비율이 높았던 하위 5개 측정소(관악구, 서초구, 성북구, 마포구, 서대문구 측정소)를 포함하였다. 그림 7은 선정된 10개 측정소의 위치지도이다.
선정된 서울시내 10개 대기질 측정소 농도 자료에 임의로 결측치를 생성하고, 각 내삽 방법으로 내삽을 진행한 결과는 표 4, 표 5와 같다. 내삽 정확도를 비교하는 성능 지표는 앞선 연구에서 활용된 RMSE, MAE, RMSLE 값을 활용하였다.
표 4.
상위 5개 측정소 지점에 대한 결측치 내삽 결과 정확도 비교
표 5.
하위 5개 측정소 지점에 대한 결측치 내삽 결과 정확도 비교
표 4에서 세 가지 지표를 모두 확인했을 때, 결측 비율이 낮은 경우 전반적으로 본 연구에서 제안하는 신경망 모형의 내삽 정확도가 4가지 방법 중 가장 높았다고 볼 수 있다. 특히, 노원구 측정소, 중구 측정소, 용산구 측정소는 모든 성능 지표에서 신경망 모형의 정확도가 가장 높다고 계산되었다. 표 5에서 결측의 비율이 높았던 하위 5개 측정소의 경우 특정한 내삽 방법이 상대적으로 우수한지 확인하기 어려웠다. 또한 상위 5개 측정소의 결과에 비해 상대적으로 낮은 정확도를 보이고 있었다.
신경망 모형의 내삽 정확도가 낮았던 측정소 중 시간 의존성을 고려하지 못하는 공간내삽 방법의 정확도가 높았던 관악구 측정소와 서대문구 측정소 중 관악구 측정소에 대해, 해당 측정소에 추가적인 영향을 미칠 가능성이 있는 공간적 특성이 존재하는지 그 여부를 검토하였다. 이때 DEM과 토지피복지도를 통해 측정소 주변의 지형적 특성과 토지 이용 정보를 활용하였다. 또한 본 연구의 대상 측정소로 주로 다루었던 동대문구 측정소 주변의 지형 및 토지 이용 현황을 함께 확인하고, 이를 통해 도출된 공간적 특성을 신경망 모형의 내삽 정확도가 낮은 관악구 측정소와 비교하였다. 그림 8, 그림 9는 각각 관악구, 동대문구 측정소 주변의 지형 및 토지 이용 정보를 보여주는 지도이다.
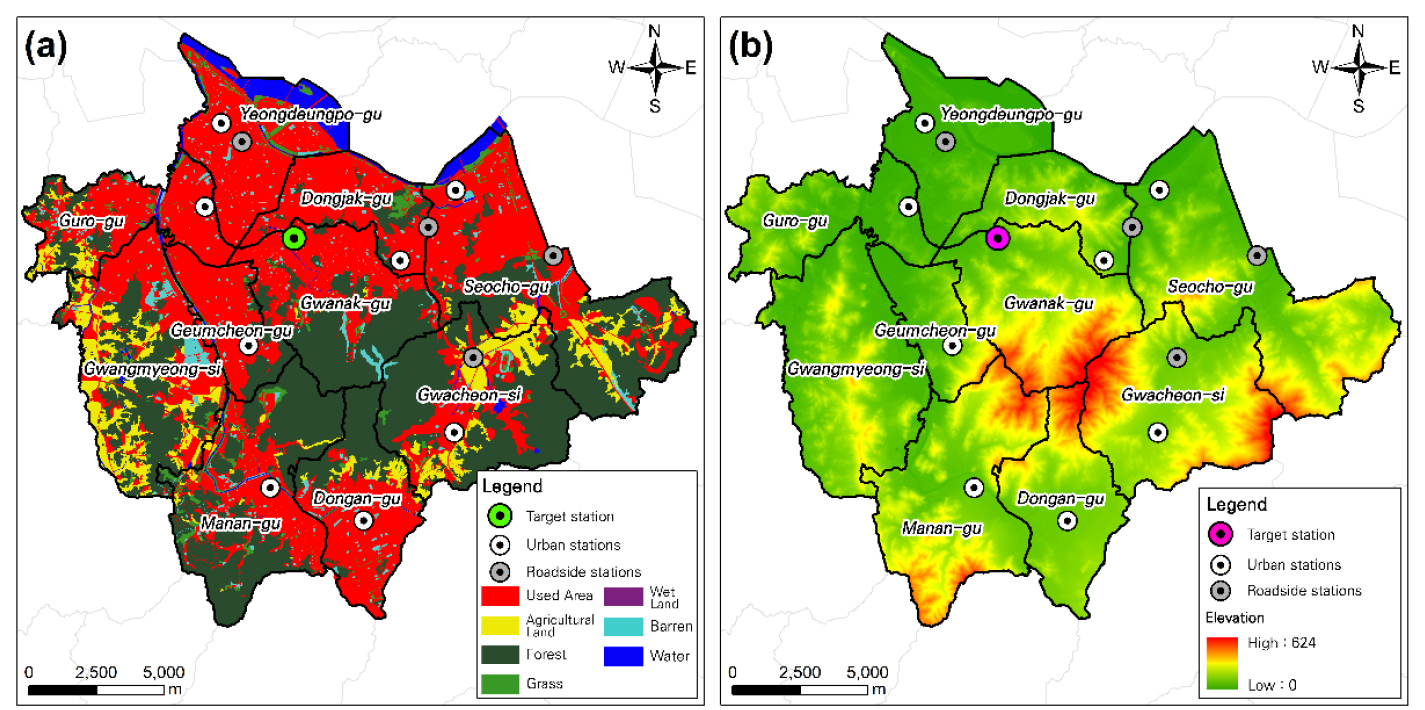
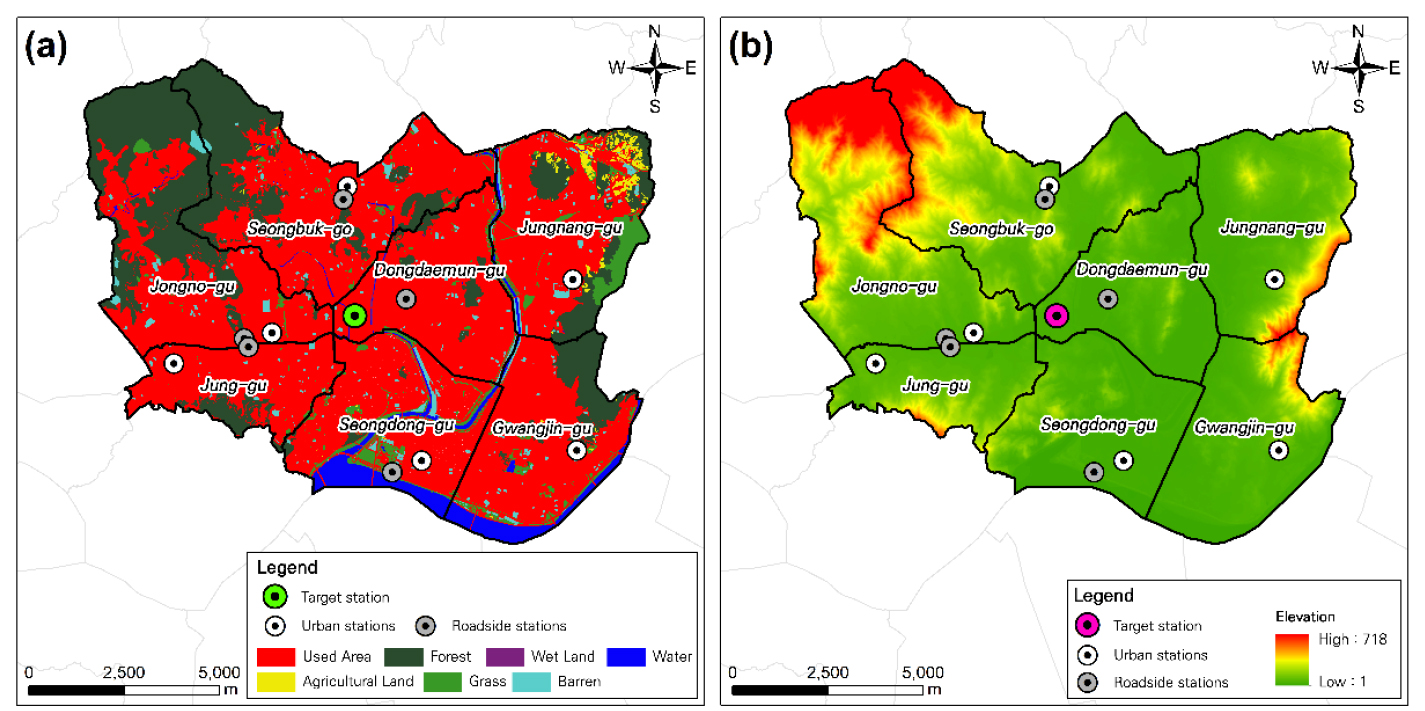
먼저, 그림 8은 신경망 모형의 정확도가 낮았던 관악구 측정소 주변의 지형 및 토지 피복 정보를 보여준다. 이 측정소는 이웃 측정소와 대상 측정소 사이에 높은 고도의 산지가 분포해 있음을 확인할 수 있다. 산지와 같은 장애물들로 둘러싸인 분지 지형의 경우 복잡한 기류가 형성될 수 있는 다른 지형에 비해 미세먼지 농도의 변동이 적고, 확산이 어렵다(한승욱 등, 2015). 따라서 측정소 별 미세먼지 농도 변화 패턴에 차이를 가져올 수 있다. 관악구 측정소의 경우 지형 및 토지 피복만을 고려했을 때 관악구 측정소와 유사한 농도 분포를 가질 수 있는 측정소는 산지로 둘러싸여 있지 않은 관악구 측정소를 기준으로 북쪽에 위치한 이웃 측정소라고 볼 수 있다. 연구에서 제시한 신경망 모형은 거리 등을 고려하여 이웃 측정소를 선정하고 해당 측정소의 농도를 활용하기는 하지만, 이웃 측정소들과 대상 측정소 간 상대적인 거리나 고도 등을 인식할 수 있도록 설계되어 있지는 않기 때문에 관악산 이남과 관악구 측정소 북측의 측정소 모두 계산 과정에서 동일한 영향을 미쳤을 것이며, 이러한 한계점이 내삽 결과에 작용했으리라고 볼 수 있다.
반면 그림 9에서 확인할 수 있듯이 내삽 대상 측정소인 동대문구 측정소는 해당 측정소와 이웃 측정소 사이에 고도가 높은 산지 지형이 없는 것을 확인할 수 있다. 또한 지도 상으로 확인 가능한 모든 측정소가 위치하는 지점의 토지 피복 분류도 대부분 시가화 지역인 것을 알 수 있다. 대상 측정소와 가장 가까운 측정소는 동대문구에 위치한 홍릉로 도로변 대기 측정소인데, 만약 홍릉로 측정소와 동대문구 측정소의 농도 분포가 상이한 패턴을 보일 경우 IDW 내삽 방법의 정확도는 낮아질 것이다. 본 연구에서 제안한 신경망 모형은 동일한 시점에서의 가장 가까이 있는 측정소의 농도 뿐만 아니라 이전 시점의 대상 측정소 농도의 변화 패턴을 함께 고려할 수 있는, 시간 의존성을 고려하는 모형이기 때문에, 다음과 같은 상황에서 기존의 공간 내삽 기법에 비해 높은 정확도를 확보할 수 있다.
5. 결론 및 시사점
본 연구는 미세먼지 농도 자료의 활용성을 높이기 위한 농도 결측 지점의 내삽 방안을 제시하였다. 이를 위해 미세먼지의 시공간 의존성을 모두 고려할 수 있는 내삽 방법의 입력 인자 선정 및 제작 과정에 대해 논의하였다. 시간 의존성을 고려하는 신경망 모형인 LSTM 모형을 기반으로, 제작된 신경망 모형의 입력 데이터로 미세먼지 농도 추정 연구에 주로 활용되는 기상 자료와 함께, 이웃 대기질 측정소의 농도 자료와 내삽 대상 측정소의 공간적 자기상관 지수 자료를 사용함으로써 미세먼지의 공간 관계를 고려하였다. 제작된 모형을 통해 내삽된 농도 자료 결측의 정확도를 공간 내삽 기법의 내삽 결과와 비교함으로써 본 연구의 시간 내삽 모형이 내삽 결과에 공간 관계를 얼마만큼 반영할 수 있는지 확인하였다.
미세먼지 농도의 결측치 내삽은 다음과 같이 진행하였다. 먼저 선정된 입력 자료의 조합별 신경망 모형의 학습 과정을 확인함으로써 내삽을 위해 가장 적합한 입력 자료 구성을 결정하였다. 최종적으로 선정된 입력 자료 조합의 모형은 기상 자료, 이웃 측정소 자료, 자료를 입력 데이터로 사용하는 모형이다. 다음으로, 본 연구의 내삽 대상 측정소인 서울시 동대문구 측정소 농도 자료에 대해 임의의 결측을 생성하고, 해당 지점에 대해 내삽을 진행하였다. 기존의 공간 내삽 기법과 그 정확도를 비교한 결과, 연구에서 제안한 신경망 모형의 내삽 정확도가 가장 좋았으며, 임의 결측 시점에 대한 내삽 결과를 포함하는 농도 지도를 작성했을 때 공간 내삽의 결과 패턴과 시간 내삽의 결과 패턴이 모두 고려되며 내삽이 이루어지는 것을 확인하였다.
연구에서 제안한 신경망 모형의 적용 범위를 서울시내 다른 측정소로 확장함으로써 모형의 범용성을 살펴보았다. 분석 결과 다수의 측정소에 대해 신경망 모형의 내삽 결과 정확도가 가장 높았으며, 특히 결측의 비율이 높은 측정소에 비해 결측의 비율이 낮은 측정소에 대한 신경망 모형의 내삽 정확도가 더 안정적으로 높았음을 확인하였다. 이를 통해 LSTM의 특성 상 결측이 많은 데이터의 경우 학습 데이터가 줄어들기 때문에 정확도가 낮아지는 결과가 발생할 수 있음을 확인하였다. 또한 지형 고도, 토지 이용 등이 복잡하게 변화하는 지역에 위치한 측정소의 공간 관계를 연구에서 제안한 신경망 모형이 인식하는 데에는 어려움이 있을 것으로 예상할 수 있었다.
본 연구는 미세먼지 농도 자료의 특징을 고려하는 농도 결측 지점의 내삽 방안 중 하나로 신경망 모형 기반의 결측 내삽 모형을 제시하고 있다는 점에서 의의를 가진다. 본 연구에서 제시하는 결측 내삽 모형은 기존의 농도 추정 연구에서 높은 정확도를 보이는 신경망 모형을 활용하고, 측정소의 공간적 관계에 대한 정보를 포함한 입력 자료를 사용함으로써 시간 내삽을 진행하는 모형의 진행 과정에서 공간 정보를 함께 고려할 수 있다는 장점이 있다. 따라서 본 연구에서 제안한 방법, 즉 공간 데이터를 입력자료로 하는 LSTM 모형을 이용하여 미세먼지 농도의 결측치를 보다 정확하게 내삽한다면 다양한 미세먼지 연구에서 그 분석 결과의 신뢰도를 향상시킬 수 있을 것이다.
